
run 命令全流程:从 opencode 到 Agent Loop
如果你要设计一个能从终端命令一路走到 AI Agent 循环的架构——用户敲一行 opencode run "fix this bug",你的系统怎么把这个字符串变成一次完整的 LLM 推理?
你可能会想:这有什么难的?process.argv 解析一下,switch-case 分发,函数里调 LLM,完事。
对,但如果你的 CLI 有 20+ 个选项、3 种交互模式(非交互/本地交互/远程附加)、还需要加载完整的项目上下文(配置、插件、Provider)——switch-case 会在第 5 个选项时变成一团浆糊。
opencode 的作者也经历了这个演变。前两篇拆了 yargs 注册 和 bootstrap 初始化,现在看它们怎么汇合成一条完整链路——从 opencode 到 Agent Loop。
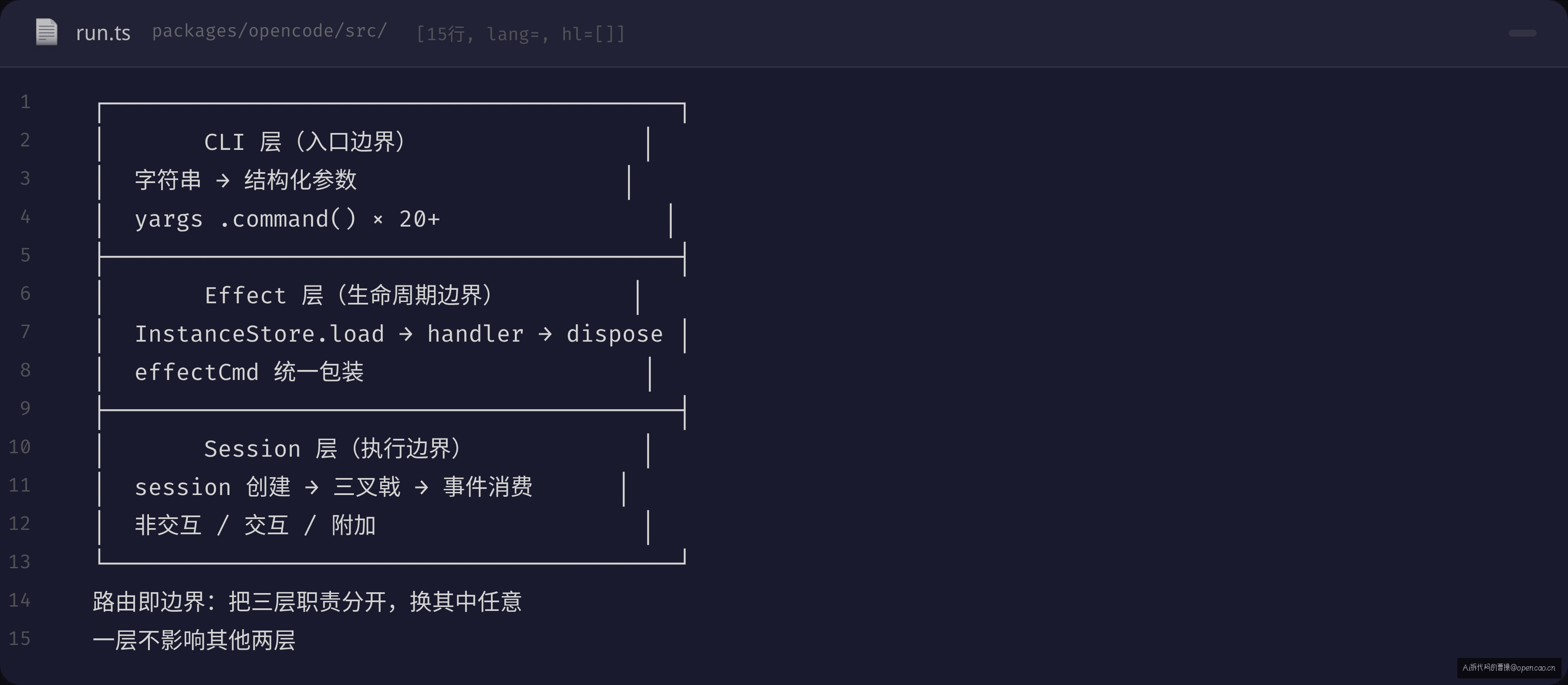
【问题】——为什么一个 run 命令需要三层路由?
naive 方案:process.argv + switch-case 的终点
如果你只做一次 LLM 调用,的确不需要三层。一个脚本就够了:
const args = process.argv.slice(2)
if (args[0] === 'run') {
const message = args.slice(1).join(' ')
const result = await callLLM(message)
console.log(result)
}
这个方案在三个维度上同时失效。
第一,参数爆炸。opencode 的 run 命令有 20+ 选项:--model、--agent、--interactive、--format json、--file、--continue、--session、--fork……每个选项有自己的类型、别名、默认值、互斥规则。手写解析器到第 5 个选项就开始出现 undefined is not a function。相比之下,yargs 的声明式路由把 20+ 选项每一行一个 .option() 搞定。
第二,生命周期。run 需要一个完整的项目上下文——配置加载、插件初始化、Provider 注册。如果不加载,LLM 调用连 API key 都找不到。如果加载完不释放,下次启动内存泄漏。
第三,模式分裂。同一个 run 命令要同时支持:非交互式(发一条消息就退出)、本地交互式(开 TUI 持续对话)、远程附加式(连到已运行的 server)。三种模式共享 80% 的 session 逻辑,但输出处理和生命周期完全不同。
三个人在三个 PR 里往同一个 switch-case 加代码——这就是 opencode 选择三层路由的直接原因。
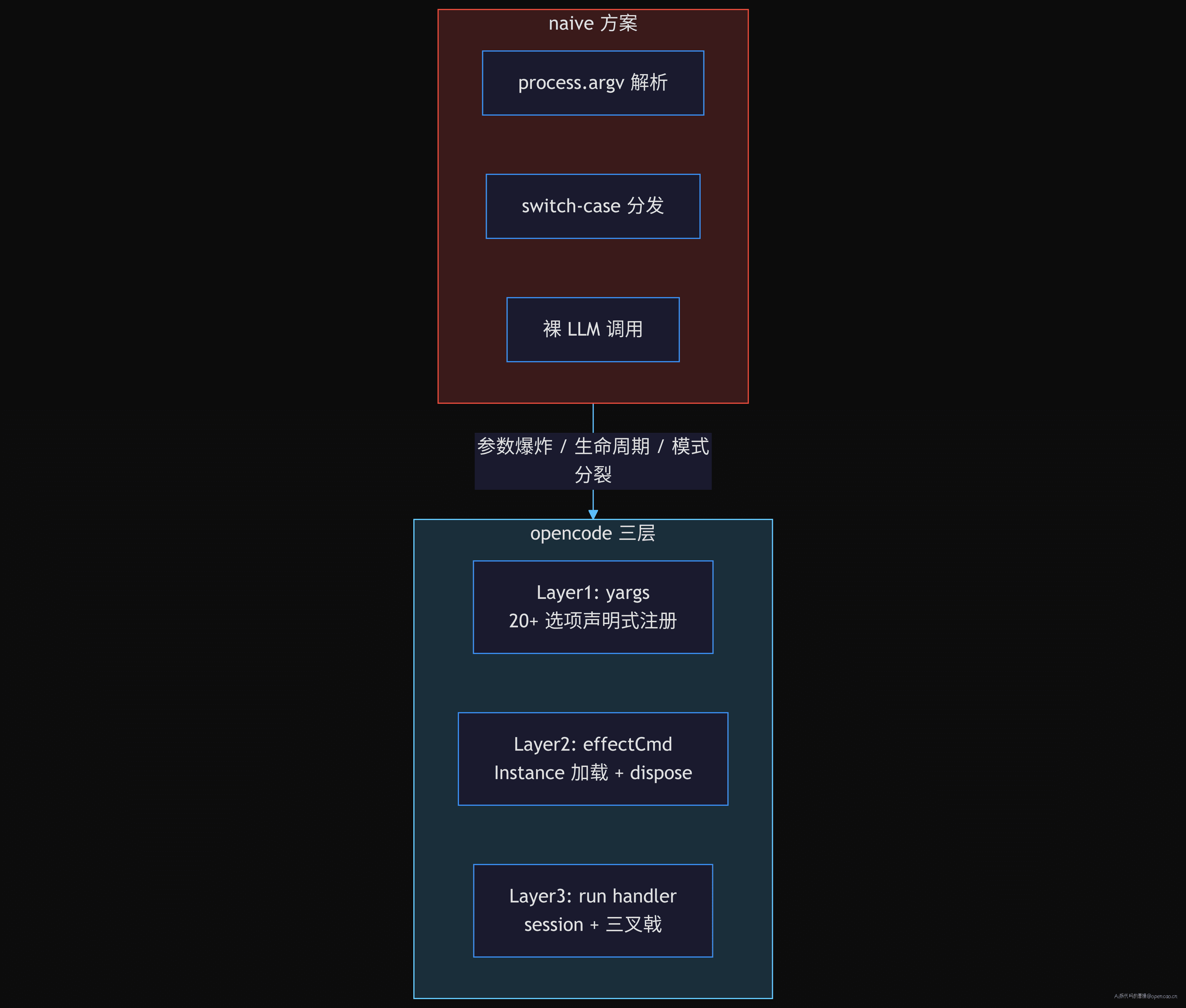
opencode 的选择:CLI 层 → Effect 层 → Session 层的三层过滤
三层不是拍脑袋分的,每一层解决一个维度的问题:
| 层级 | 文件 | 职责 | 解决 naive 的哪个痛点 |
|---|---|---|---|
| Layer 1: CLI 层 | src/index.ts |
yargs 声明式注册 + 参数解析 | “参数爆炸”——20+ 选项每行一个 .option() |
| Layer 2: Effect 层 | src/cli/effect-cmd.ts |
InstanceStore 加载 + 自动 dispose | “生命周期”——Effect.ensuring(Effect 的 finally 等效机制,保证退出时执行清理)兜底清理 |
| Layer 3: Session 层 | src/cli/cmd/run.ts |
session 创建 + 三叉戟执行 | “模式分裂”——非交互/交互/附加各自走不同路径 |
这不是最优解——它多了一些间接层,每层都有抽象成本。但它在"可扩展性"和"正确性"上赢回了这些成本。继续看每层的具体代码。
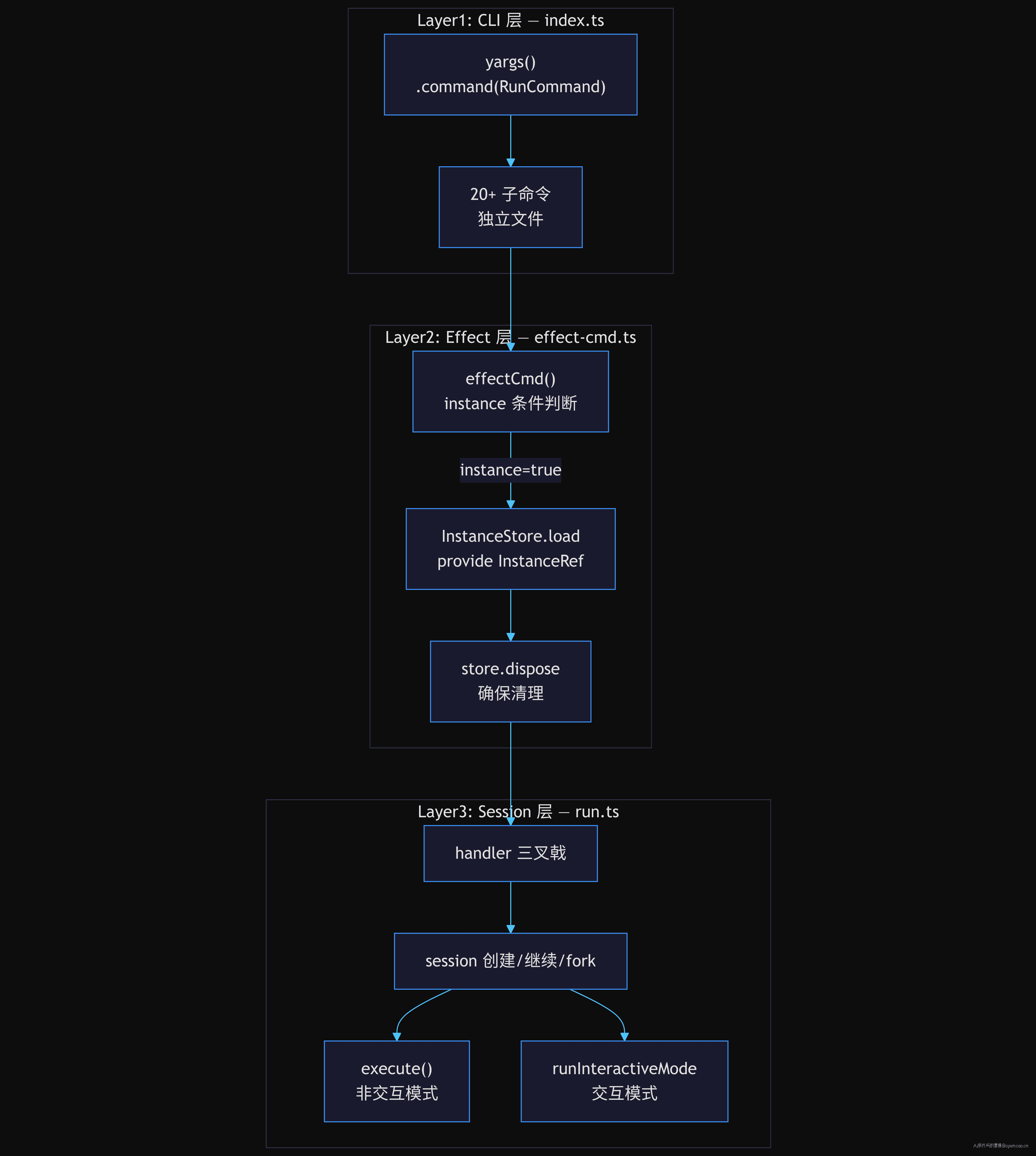
【设计】——三层架构各层职责
Layer 1:yargs builder 声明式注册
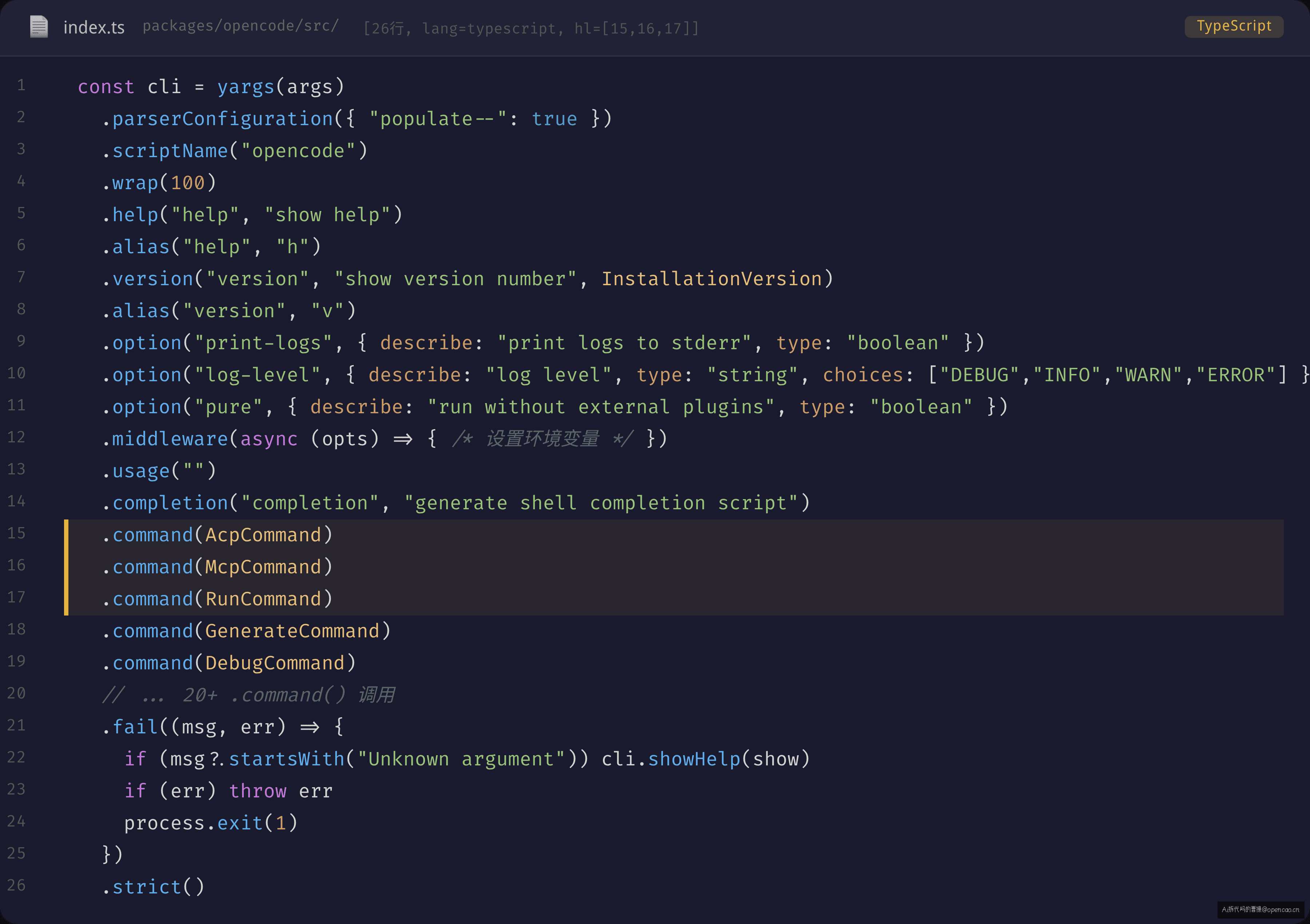
入口文件 src/index.ts 是这个 CLI 的"路由表"。45 行代码注册了 20+ 个命令,每个命令一个 .command() 调用(sources/opencode/packages/opencode/src/index.ts L45-116)。
如果你熟悉 02-01,这里不加新东西。关键是第 85 行 .command(RunCommand)——RunCommand 不是普通 yargs 命令对象,它是用 effectCmd() 包装过的。
这里有一个容易忽略的设计细节:.middleware() 注册在全局 cli 上,但它只在 yargs 完成参数解析 之后 执行。这意味着 middleware 可以读到所有 flag 的值。opencode 利用这一点在 middleware 里设置环境变量(OPENCODE_PRINT_LOGS、OPENCODE_LOG_LEVEL),确保这些配置在 handler 被调用之前就已生效。
你可能会问:既然 .middleware 能做到,为什么不把 InstanceStore 加载也放进 middleware?因为 middleware 无法被 effect-cmd 的 finally 覆盖——如果 middleware 里加载了 Instance 但 handler 抛异常,没有 Effect.ensuring 兜底,dispose 会漏掉。
Layer 2:effectCmd 包装器
effectCmd 是连接 yargs 世界和 Effect 世界的桥梁。它做的事可以用一句话说清:
帮你加载 InstanceContext,然后调用你的 handler,最后确保 dispose。
(sources/opencode/packages/opencode/src/cli/effect-cmd.ts L69-95)
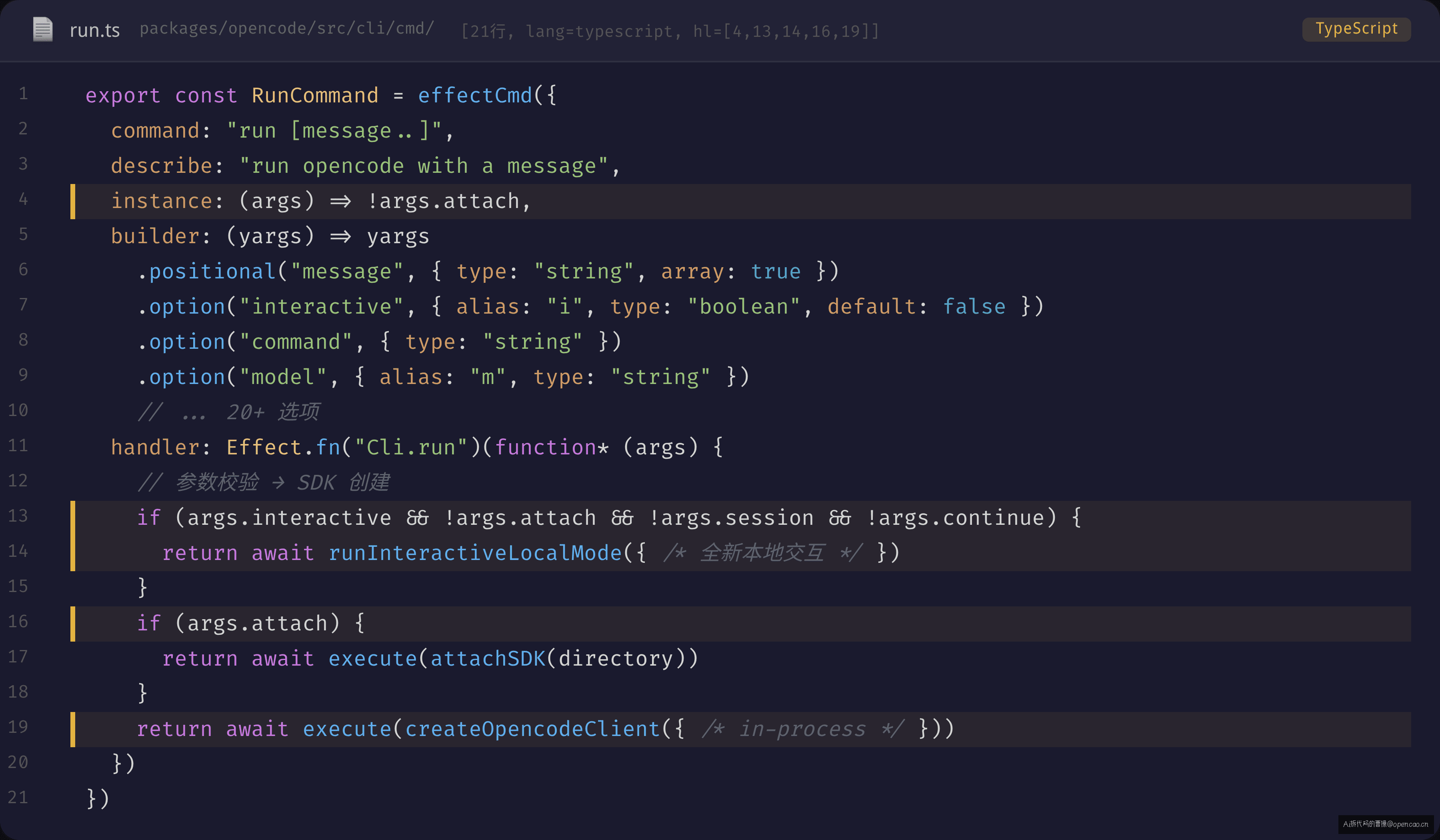
这里的核心机制是 instance 选项。RunCommand 是这样声明的:
instance: (args) => !args.attach,
--attach 模式连接到远程服务器,不需要本地 Instance。普通的 opencode run 则需要。这个条件写在 effectCmd 的配置里,而不是在 handler 内部判断——因为 handler 类型签名需要 InstanceRef(Effect 上下文中的实例引用),如果不加载实例,handler 里的 yield* InstanceRef(Effect 的依赖获取语法,类似 await 但用于 Effect 上下文)会直接 defect。
边界场景:如果 instance 为 true 但 store.load 失败(比如找不到项目目录),effectCmd 不会调用 handler——错误直接冒泡到 src/index.ts 的 catch 块,显示错误后 exit(1)。这比在每个 handler 里写 try-catch 更干净。

Layer 3:run handler 三叉戟
RunCommand 的 handler 是整个 CLI 最长的函数——约 650 行(L241-893)。但它不复杂,只是因为处理了三种模式的排列组合。
handler 的入口是 Effect.fn("Cli.run")(function* (args) { ... })。Effect.fn(Effect 的命名追踪机制,类似给函数贴标签,调试时一眼看出调用来源)给函数加了一个命名 span,在 Effect 追踪系统里显示为 Cli.run——调试时看 tracing 一眼就能认出这是哪个命令。
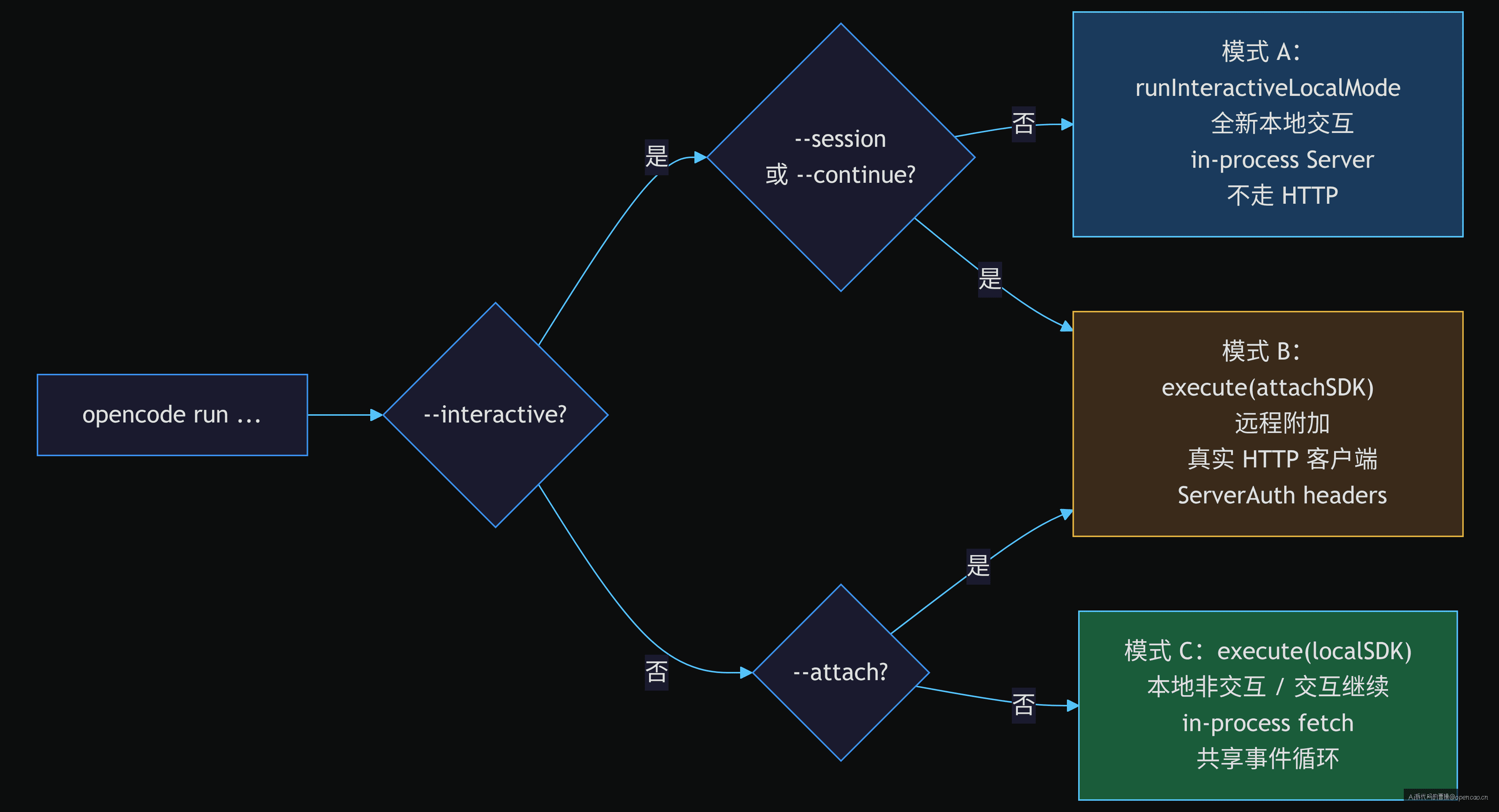
handler 的顶层逻辑是三个 if 分支,构成"三叉戟":
if (交互模式 && 本地 && 非继续) → runInteractiveLocalMode()
else if (附加模式) → execute(attachSDK)
else (默认, 含非交互和交互继续) → execute(localSDK)
这个判断不是随意分的。(sources/opencode/packages/opencode/src/cli/cmd/run.ts L837-893)
模式 A 是"开新局"——创建全新的交互式 session,用 in-process server(不走 HTTP,通过 fetch function 直接调用 Server 的 app.fetch)。模式 B 和 C 都走 execute(),但区别是 SDK 绑定对象不同:B 走 HTTP,C 走 in-process。
为什么模式 A 要单独抽出来?因为 runInteractiveLocalMode 内部做了三件事:
- 启动 in-process Server(
Server.Default()) - 创建 session
- 直接进入交互式 TUI
而 execute() 的设计是"先创建 session,再根据参数决定怎么执行"——它更通用,但多了一个 session 创建→等待的步骤。纯 --interactive 场景下这个等待是多余的。
【源码】——主流程三块骨架
session 解析:创建 / 继续 / fork
execute() 的第一步是拿到一个 session ID。session() 函数(sources/opencode/packages/opencode/src/cli/cmd/run.ts L391-468)处理了 7 种排列组合:
这里的 fork 是一个有意思的设计。它不是简单的"复制 session",而是创建一个新的空 session 但继承原 session 的 title 和 directory。目的是让你在同一个项目里开一个"平行时空"继续调试,不影响之前的对话历史。
naive 方案不会考虑 fork——因为单次 LLM 调用不需要。但 opencode 的目标是一个持续数小时的交互式 session,用户可能需要"回到上一个决策点重来"。fork 就是这个重来机制的基础。

执行分叉:command / prompt / 交互
想象你敲了 opencode run --command /review。你期待的是:直接执行 code review,不开新的对话轮次。但如果你敲的是 opencode run "帮我 review 这段代码",你期待的是:LLM 理解上下文后给出建议。
这两个都是"run",但底层 API 完全不同。看看 opencode 怎么处理的:
有了 session ID, execute() 根据参数走三条路径(sources/opencode/packages/opencode/src/cli/cmd/run.ts L763-834):
路径 A 和 B 的区别是 API 语义不同:session.command() 发送的是"命令"(如 /review、/commit),session.prompt() 发送的是普通文本消息。但底层走的都是同一条事件流。
三个路径共享 events 订阅和 loop()。loop() 是一个 for await...of 循环,消费 SDK 返回的 event stream,根据事件类型决定是打印文本、显示工具调用、还是处理权限请求。
naive 方案不会区分 command 和 prompt——一个 prompt 函数就够了。但 opencode 需要让 slash command 有特殊的执行语义(比如不开启新 turn、直接返回结果),所以才分了两个 API。

事件循环:loop() 流式消费
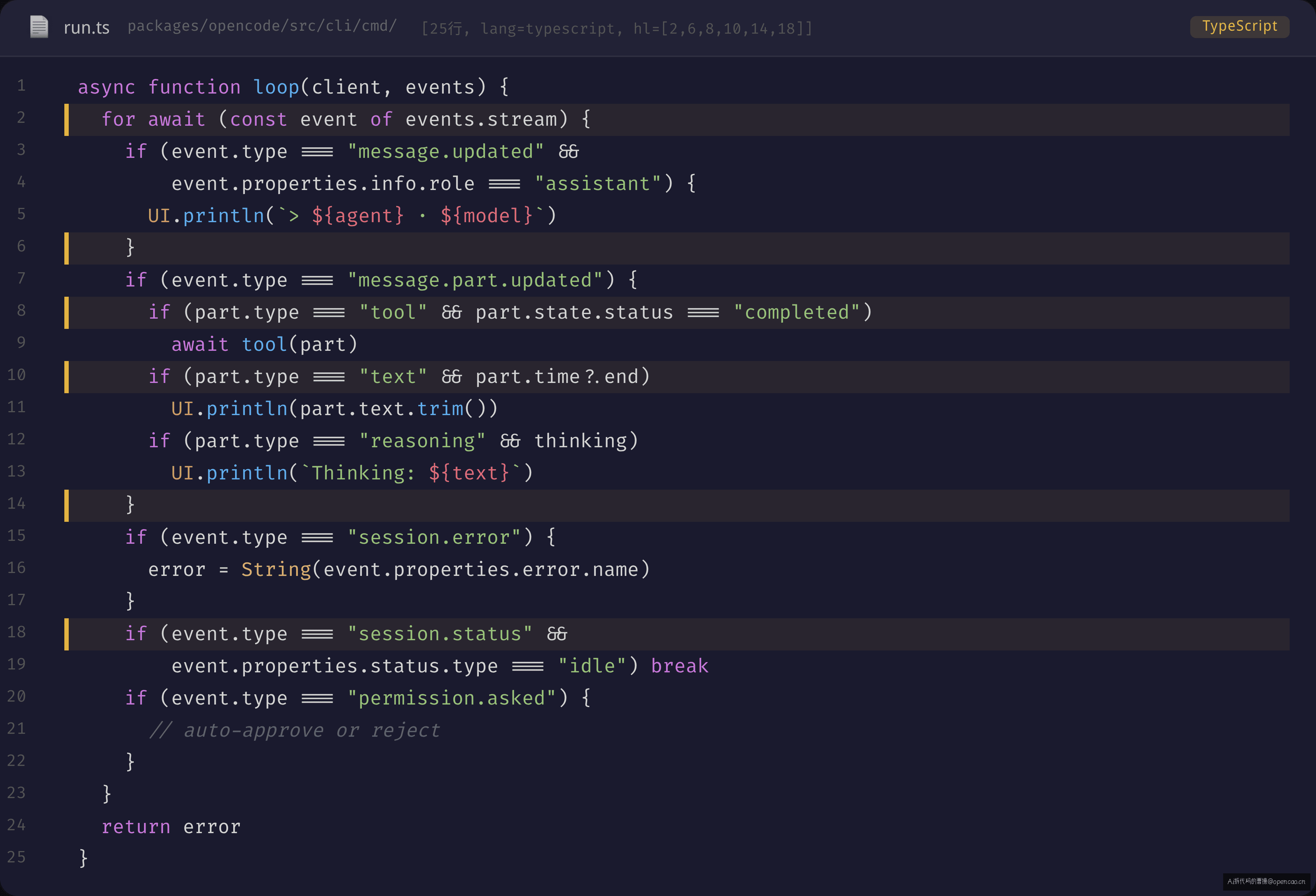
loop() 函数(sources/opencode/packages/opencode/src/cli/cmd/run.ts L632-753)是整个 run 命令的输出处理核心。它订阅 session 的事件流,在 for await...of 里处理 9 种事件类型:
这个循环的优雅之处在于它是同构的——非交互模式和交互模式都用同一套事件模型。区别只在于消费方式:非交互模式下 loop() 直接打印到 stdout,交互模式下事件被转发到 TUI 组件(如 RunFooter 的 event() 方法)。
naive 方案可能会用 callback 或 Promise chain 来输出流——每个事件一个 .then()。但对 9 种事件类型和 7 种筛选条件来说,callback 地狱比 for await...of 难读 10 倍。
【权衡】——三层路由 vs 扁平方案
可扩展性:每命令独立文件 vs 一个巨大 switch
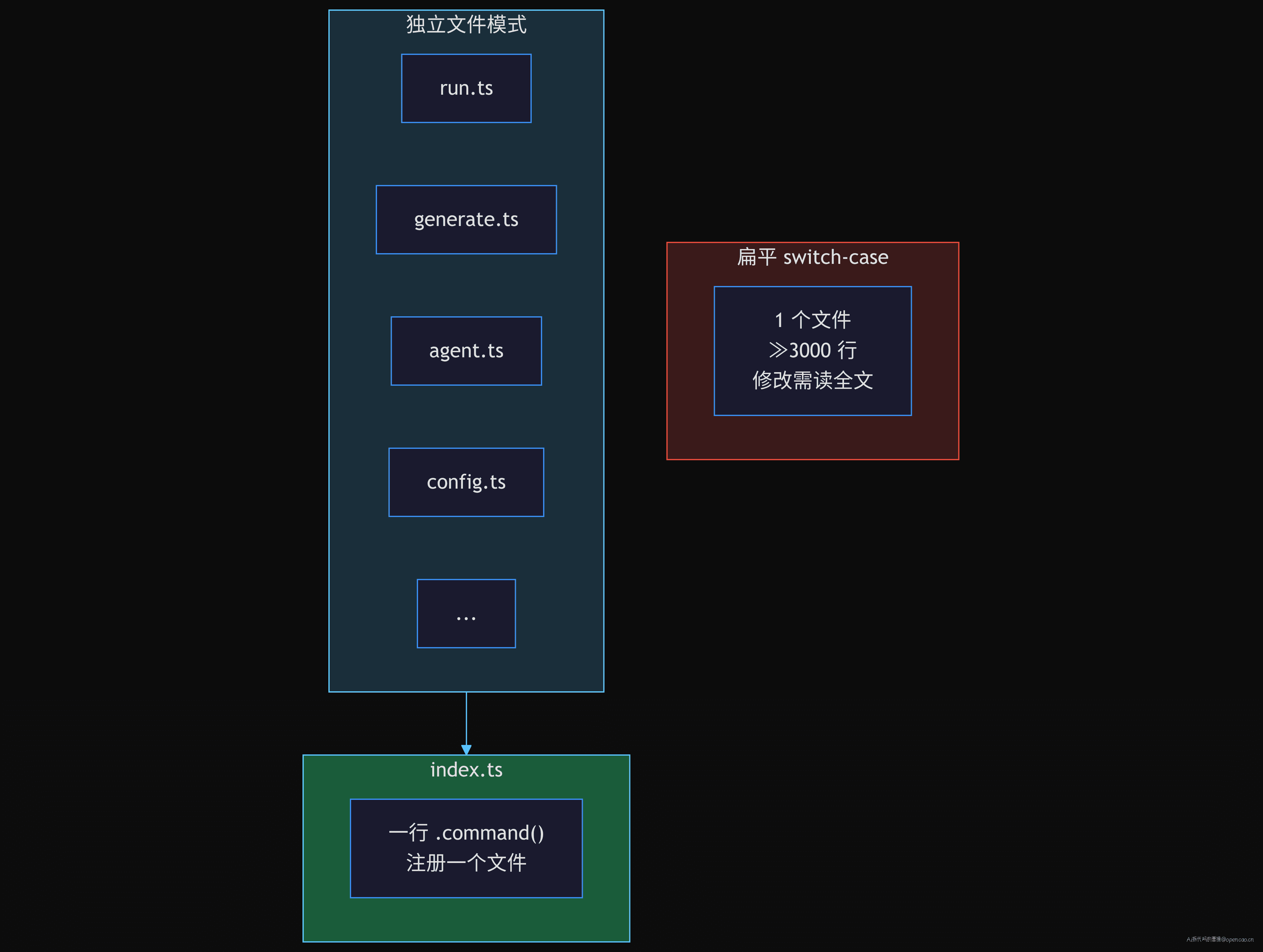
扁平方案如果只支持 3 个命令,100 行代码搞定。但 opencode 有 20+ 个命令,如果在一个文件里,会超过 3000 行。
opencode 的选择是每个命令一个文件,通过 effectCmd 统一接口:
src/cli/cmd/
run.ts ← effectCmd + handler 650 行
generate.ts ← effectCmd + handler
agent.ts ← effectCmd + handler
config.ts ← effectCmd + handler
session.ts ← effectCmd + handler
...
新增一个命令 ≈ 创建一个文件 + 在 index.ts 加一行 .command()。不需要修改已有代码。
代价是增加了间接层。新手第一次看代码需要理解 effectCmd 的 instance、directory、builder、handler 四个配置项分别控制什么。但对比"在一个 3000 行文件里搜 case 'run'",这点学习成本是值的。
这种「按职责切层」的架构思路在提高生产力的开源项目里反复出现。类似的架构权衡在公众号 Ai拆代码的曹操 每周拆解——关注后回复"路由"获取完整架构图集。
生命周期:effectCmd 自动 dispose vs 手动清理
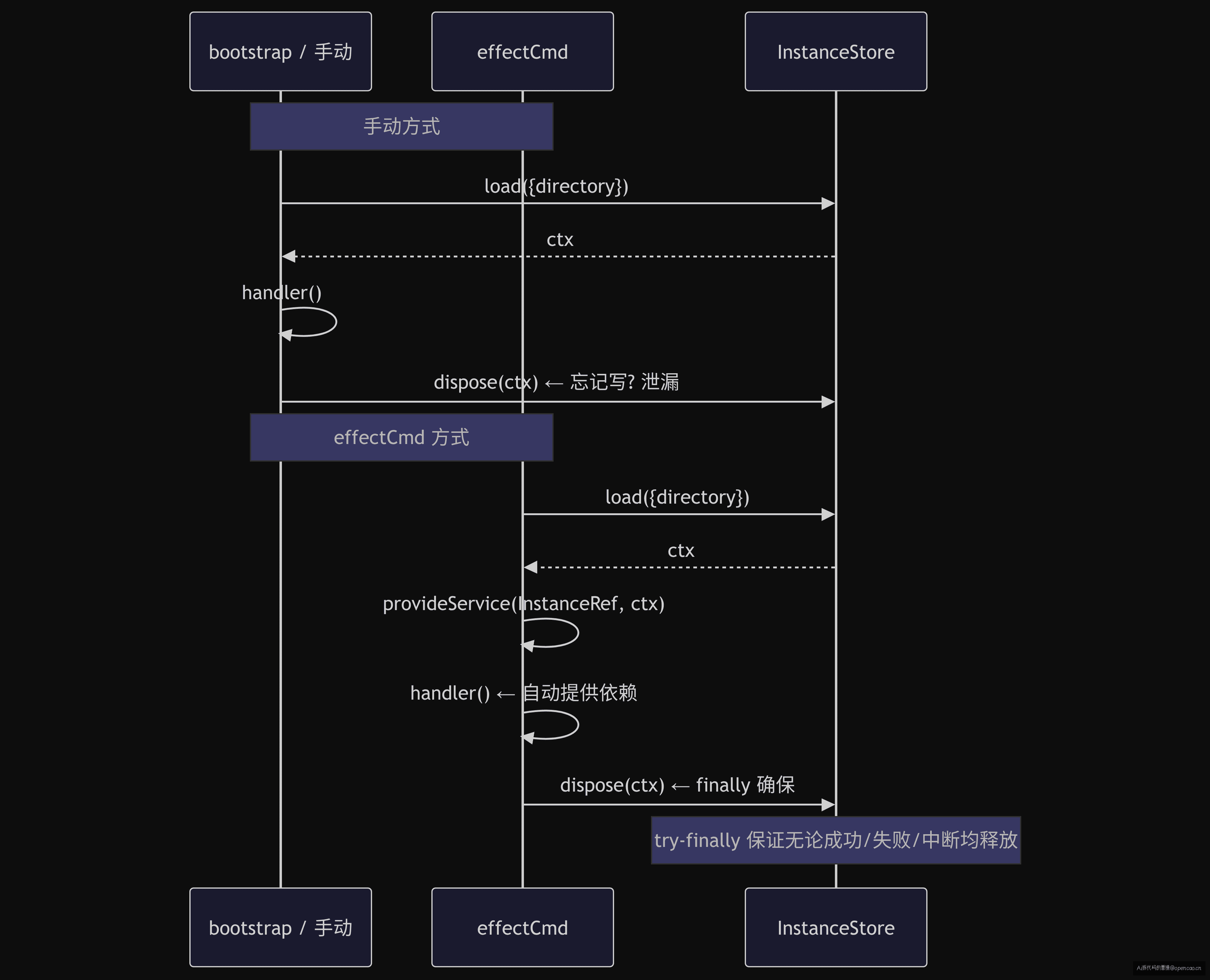
bootstrap 是 02-02 的核心函数,它做加载→执行→释放三步:
export async function bootstrap<T>(directory: string, cb: () => Promise<T>) {
const ctx = await InstanceRuntime.load({ directory })
try {
return await context.provide(ctx, cb)
} finally {
await InstanceRuntime.disposeInstance(ctx)
}
}
effectCmd 做的事情等价——但它是通用的,不需要每个命令写一遍 try-finally。如果你不用 effectCmd,在 run handler 里你也要手动 bootstrap()。
那为什么还保留 bootstrap 函数(cli/bootstrap.ts)?因为 bootstrap 不依赖 Effect 运行时(AppRuntime.runPromise 是 Effect 的入口,把 Effect 程序转换成 Promise 执行)——它是一个纯 async/await 版本,用在不需要 Effect 的简单场景(比如 stream.transport.ts 里用来执行一次性的文件操作)。
边界失效案例:如果 store.dispose 本身抛异常(比如 IPC server.instance.disposed 无法发送),effectCmd 的 finally 里的 AppRuntime.runPromise 会失败,导致 dispose 未执行。opencode 的做法是 dispose 内部 catch 所有异常,确保即使 IPC 失败也不影响内存清理。
三种交互模式为什么必须分开
看一个设问:如果 --interactive --attach 和 --interactive 走同一条路径,会有什么问题?
答案是 SDK 的创建方式不同。本地模式用 fetch function(in-process HTTP),远程模式用真实的 HTTP 客户端。这两个 SDK 的 session.command() 和 session.prompt() 接口一样,但底层传输完全不同——本地模式不经过 TCP,远程模式需要处理 ServerAuth.headers()。
naive 方案可能会把 SDK 创建放在 handler 入口,之后所有逻辑共享同一个 sdk 对象。但 opencode 的三种模式在 SDK 创建之前就有差异(目录解析、auth 头、fetch 函数等),共享反而会导致 if (args.attach) 散落在整个 handler 里。
所以作者选择了"先分叉再执行"的策略:
- 在 handler 顶部解决所有参数校验和 SDK 创建
- 三个干净的分支各自走不同的执行路径
execute()作为共享核心,处理非交互模式
【锚点】——“路由即边界”
三层路由不是过度设计——它是系统复杂度的自然映射。
CLI 层是「入口边界」:负责把字符串解析成结构化参数。不关心业务逻辑,只关心 --flag 和 <positional>。边界之外是用户的终端,边界之内是 opencode 的世界。
Effect 层是「生命周期边界」:负责加载和释放 InstanceContext。不关心命令做什么,只关心 Efffect 运行的上下文的正确性。边界之外是"未初始化"状态,边界之内是"一切就绪"。
Session 层是「执行边界」:负责把参数变成一次 Agent 循环。不关心参数怎么来的,只关心 session 创建、事件流消费、输出展示。边界之外是 CLI 参数,边界之内是 LLM 推理。
下次你设计一个需要"从终端到 AI 调用"的系统,记住三层路由的核心原则:
「路由即边界——把三层职责分开,换掉任何一层都不影响其他两层。」
不是在代码里显式写三个 class,而是在架构上把这三个职责分开。需求变了,你只需要换掉其中一层的实现。
如果你觉得这个架构模式有用,转发给你的同事——下次你们讨论"从终端到AI调用"时,就能用同一套语言对话。
下一篇拆解斜杠命令系统:/review、/commit、/diff 怎么在 run handler 的三叉戟里找到自己的位置。
📖 全文带可复现 Demo 和排查截图
🔗 个人博客:https://opencao.cn
📺 公众号:Ai拆代码的曹操
🌟 知识星球:Ai拆代码的曹操


