
maxActive=100 写在那,HikariCP 就是不认——连接池迁移遗漏引发的生产事故
本文是Spring Boot 生产配置实战系列的第 4 篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
周三上午 10:15,告警群突然响了——user-center 的 p99 响应时间飙到 5.8 秒,错误率 8.1%,大量用户登录超时。
值班小A登录监控一看,CPU 才 30.5%,load average 却高达 15.3。
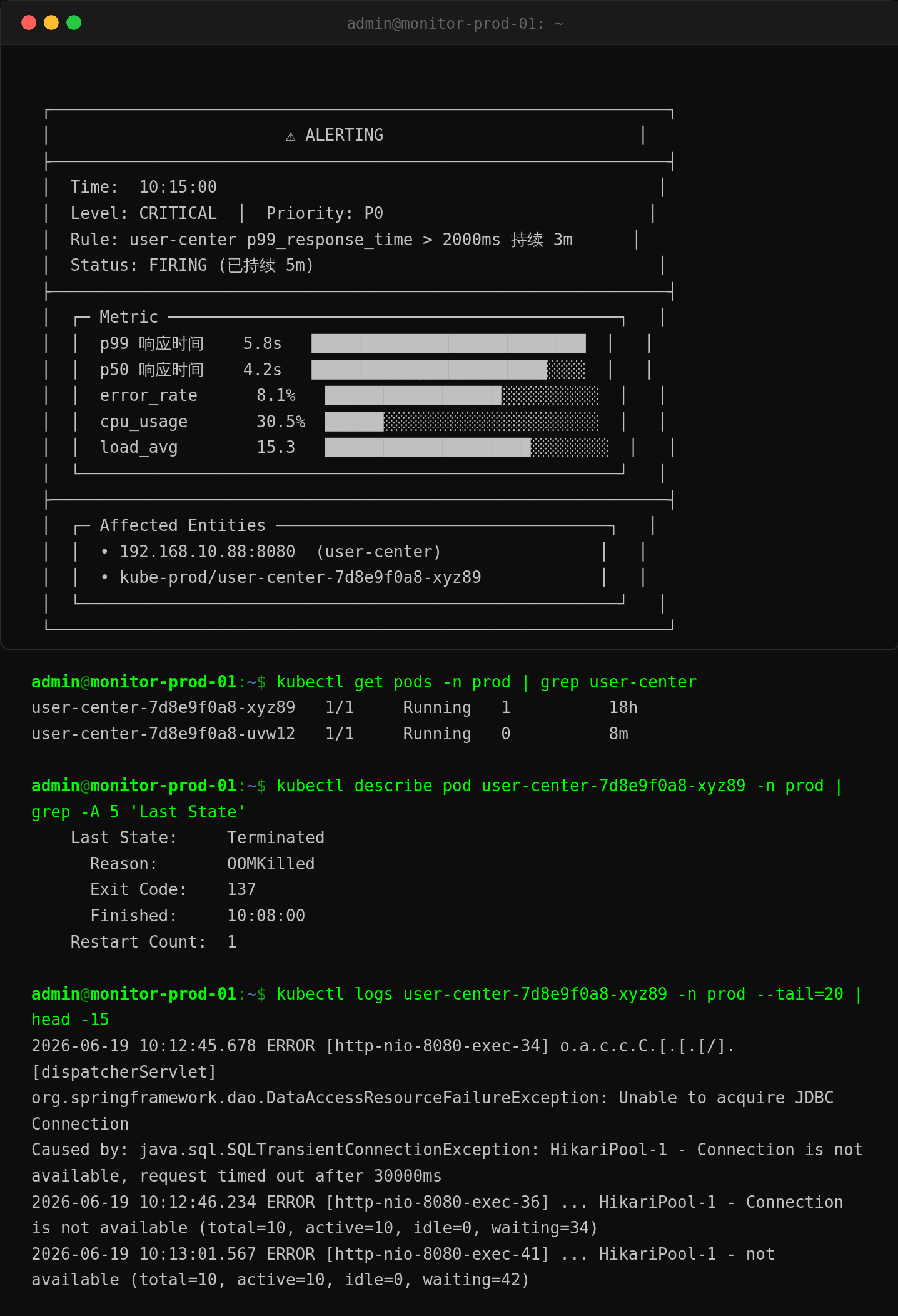
CPU 才 30%,但 load 15——明显不是计算瓶颈,进程大概率在等什么资源。
排查过程
第一步:系统层面排查
登录到 user-center-prod-01:
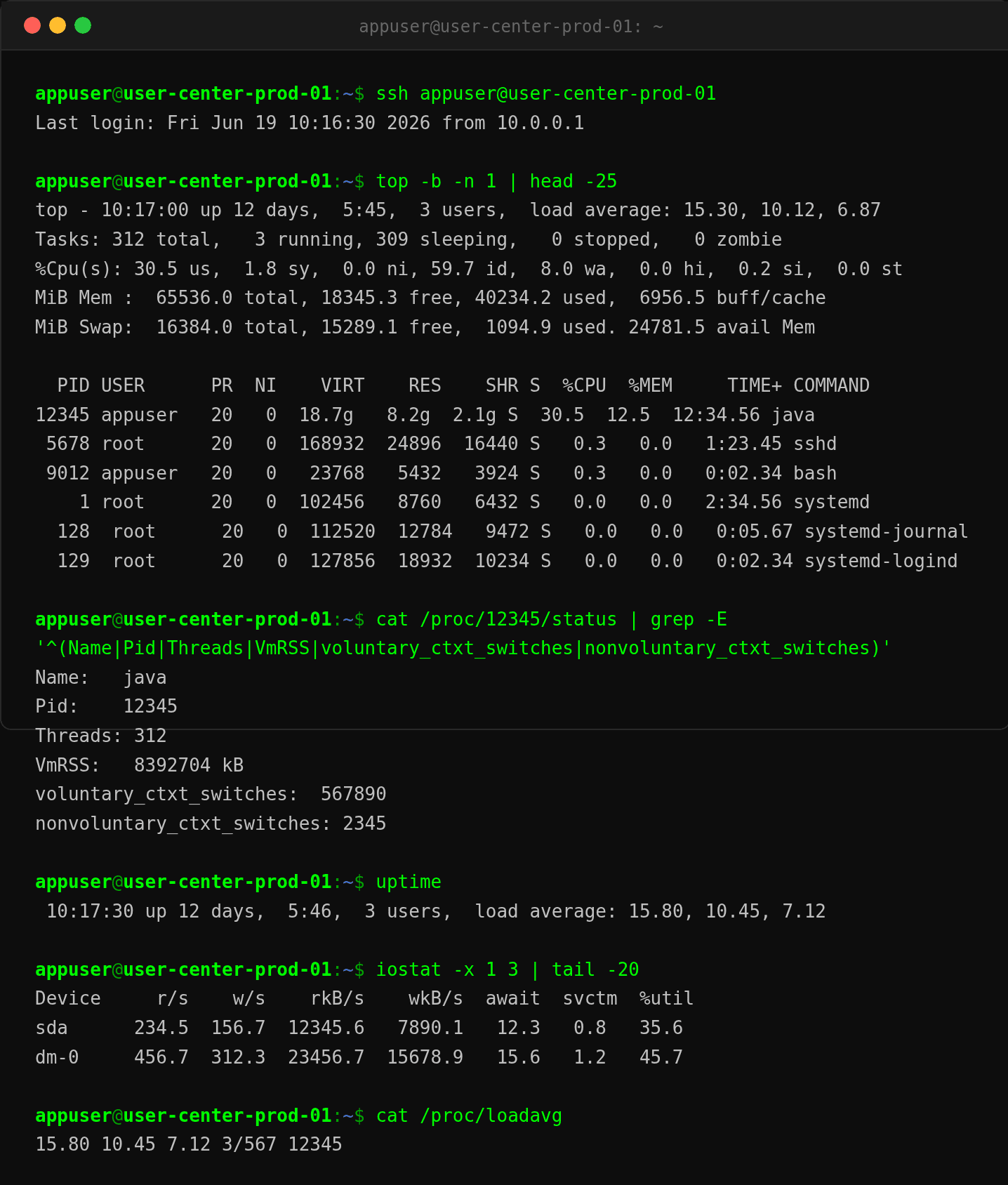
CPU 空闲 59.7%,但 iowait 8.0%,load 从 10 到 15 还在涨。RAM 和 Swap 正常。这指向 IO 层面的问题——大概率是数据库连接。
第二步:connection 数异常
跑 netstat 看 MySQL 连接:
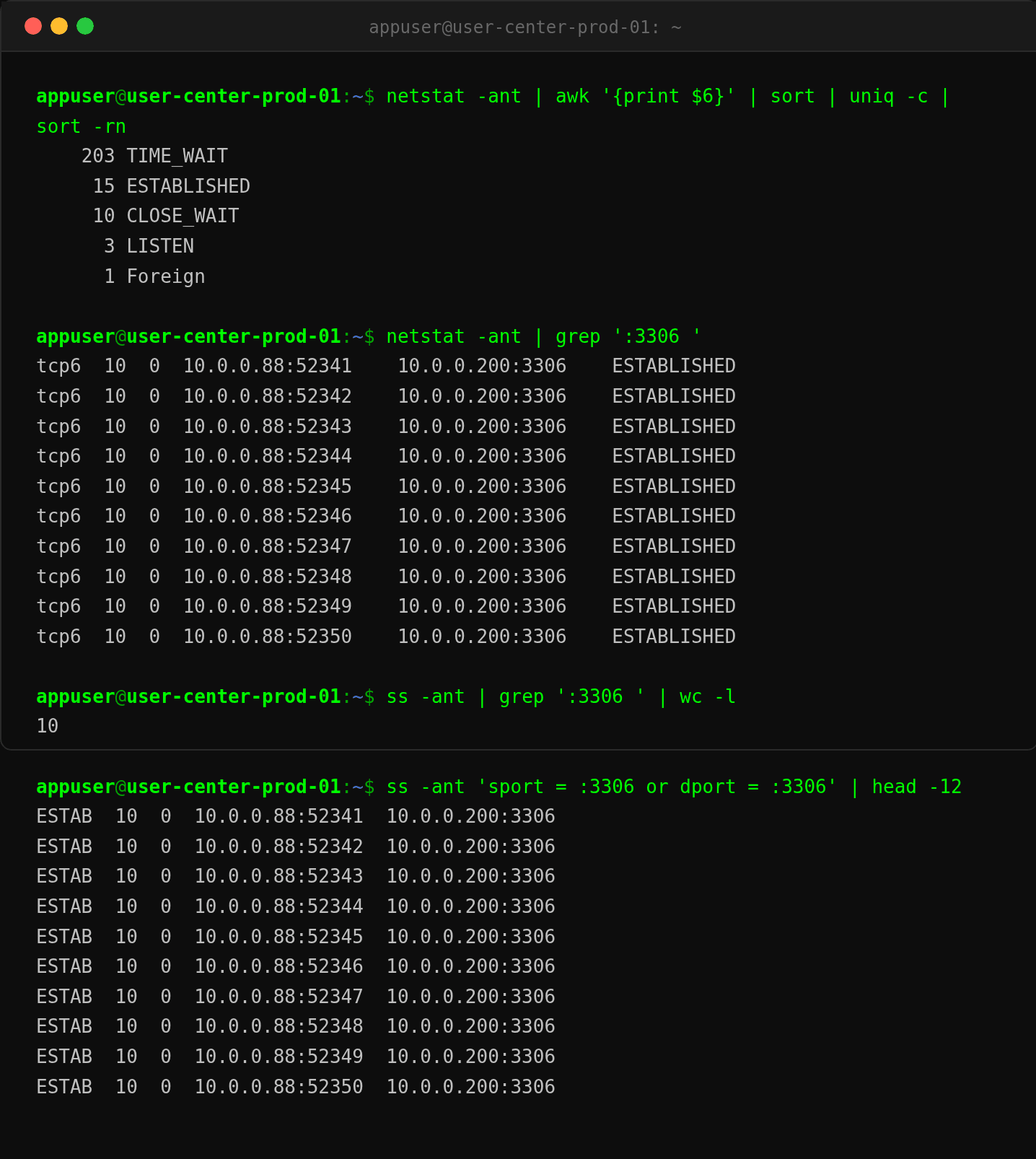
只有 10 个 MySQL 连接,全部 ESTABLISHED,没有空闲。 10 这个数字扎眼了——HikariCP 默认的 maximumPoolSize 正好是 10。
第三步:日志确认
翻应用日志,全是连接池排队超时:
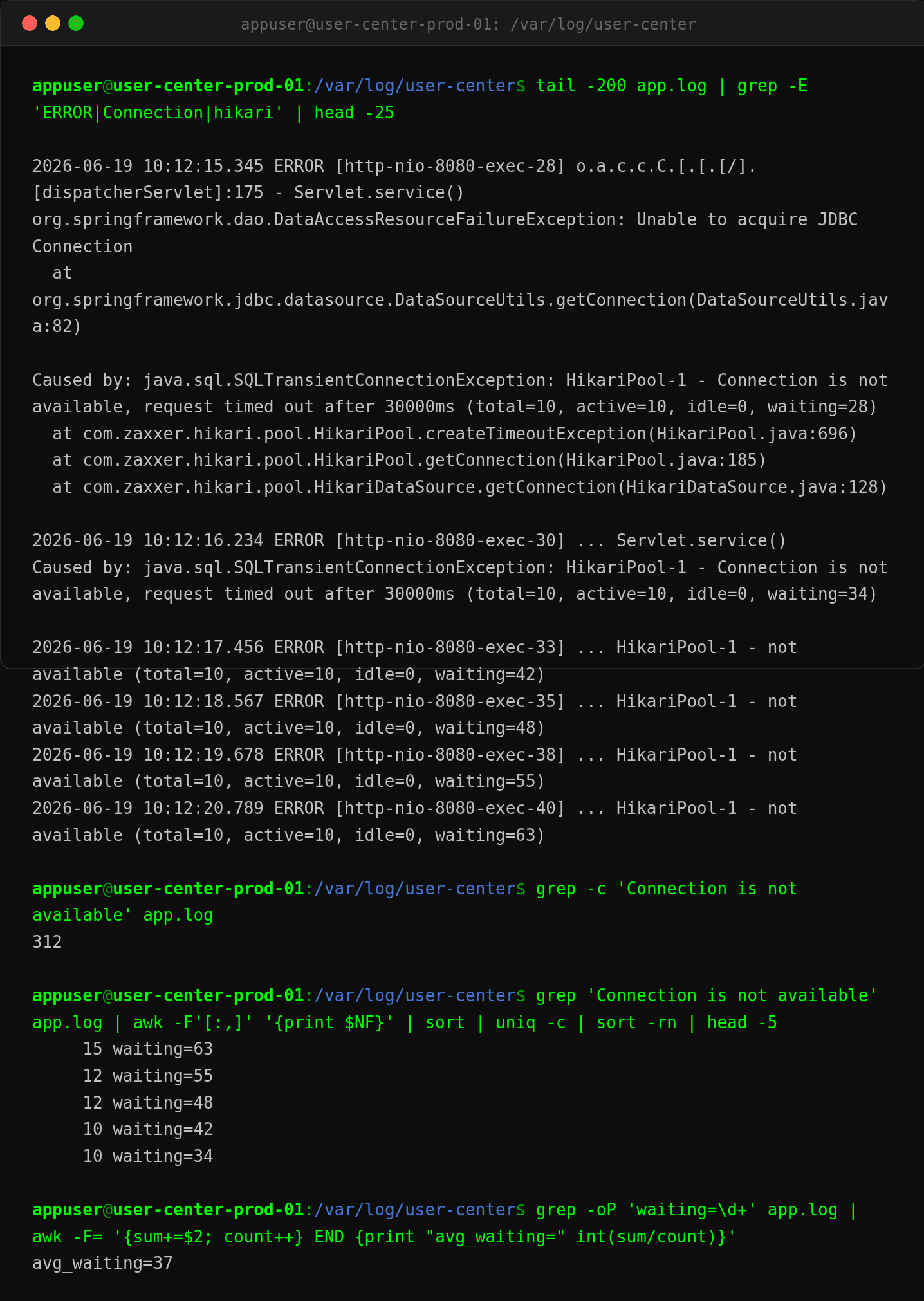
Caused by: java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available,
request timed out after 30000ms (total=10, active=10, idle=0, waiting=63)
total=10, active=10, idle=0, waiting=63——10 个连接全被占了,63 个线程在排队。
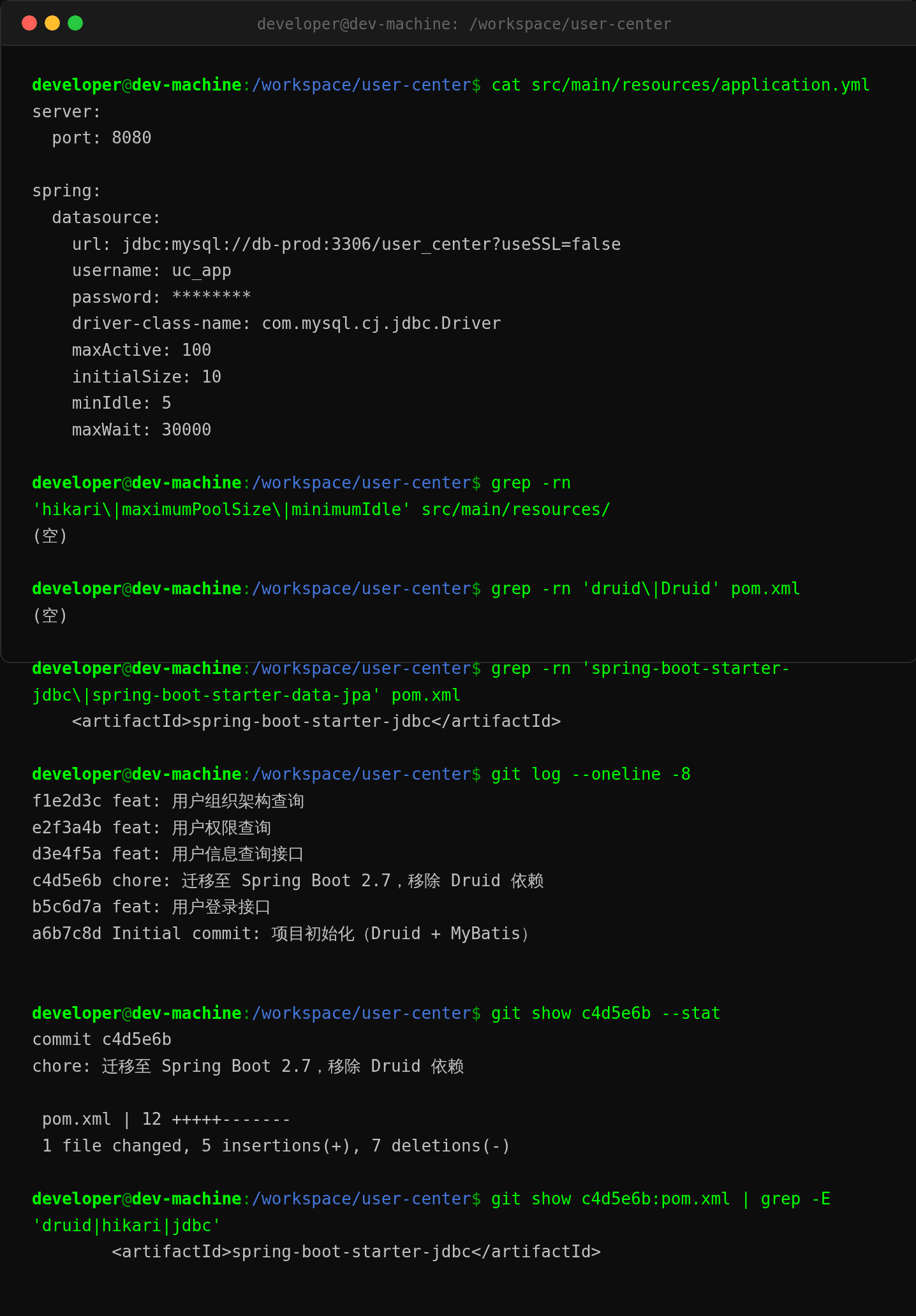
第四步:查配置,发现问题
回到开发环境看 application.yml:
spring:
datasource:
url: jdbc:mysql://db-prod:3306/user_center
username: uc_app
password: ********
driver-class-name: com.mysql.cj.jdbc.Driver
maxActive: 100
initialSize: 10
minIdle: 5
maxWait: 30000
maxActive: 100、initialSize: 10——这是 Druid 的参数!
项目以前用 Druid,迁移到 Spring Boot 2.7 时去掉了 Druid 依赖(pom.xml 改了),但 application.yml 里这些 Druid 参数全留下了。HikariCP 根本不认这些参数,静默走默认值 maximumPoolSize=10。
而且用户中心每次登录要查 3 次数据库(用户信息 → 权限 → 组织),10 个连接高峰时根本不够用。
根因分析
两层问题叠加:
第 1 层:Druid → HikariCP 迁移遗漏
$ git log --oneline -8
c4d5e6b chore: 迁移至 Spring Boot 2.7,移除 Druid 依赖
迁移只改了 pom.xml,application.yml 里的 Druid 参数 没人删、没人替换。HikariCP 启动时看到 maxActive、initialSize 等陌生参数直接跳过,没有任何 warning。
第 2 层:HikariCP 默认连接数不够
用户中心每个 POST /api/user/login 查 3 张表(user → permissions → organization),每次查都需要一个连接。加上每个查询内有 30-80ms 的等待(Thread.sleep 模拟外部调用),高峰期 30 个并发请求就能把 10 个连接打满。
连接被打满后,后续请求在 connectionTimeout=30000ms(默认 30 秒)内排队等待。前端等不了 30 秒,5 秒就超时重试→重试更多请求→排队队列暴涨→雪崩。
修复方案
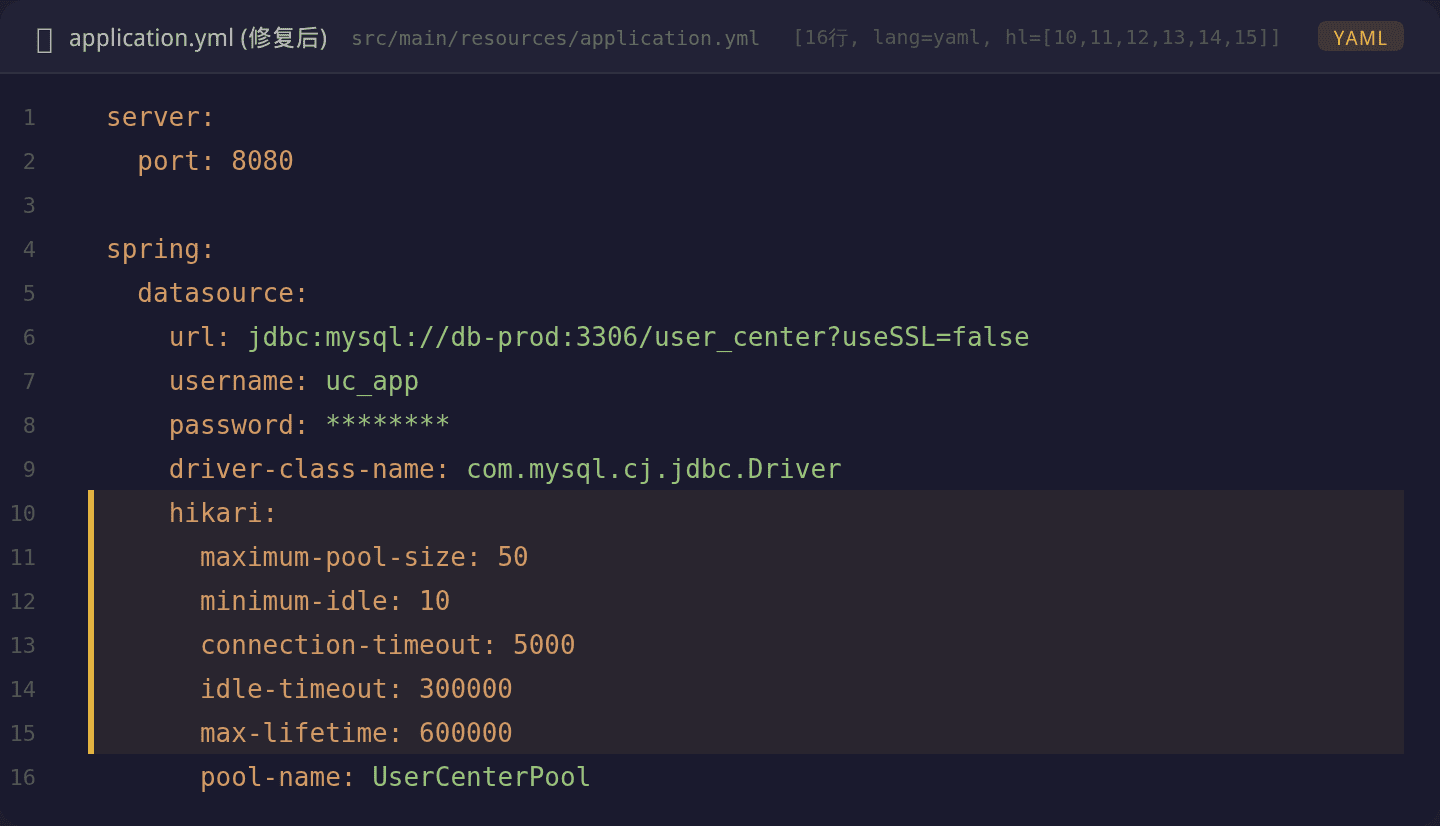
删除 Druid 参数,添加 HikariCP 配置
spring:
datasource:
url: jdbc:mysql://db-prod:3306/user_center?useSSL=false
username: uc_app
password: ********
driver-class-name: com.mysql.cj.jdbc.Driver
hikari:
maximum-pool-size: 50
minimum-idle: 10
connection-timeout: 5000
idle-timeout: 300000
max-lifetime: 600000
pool-name: UserCenterPool
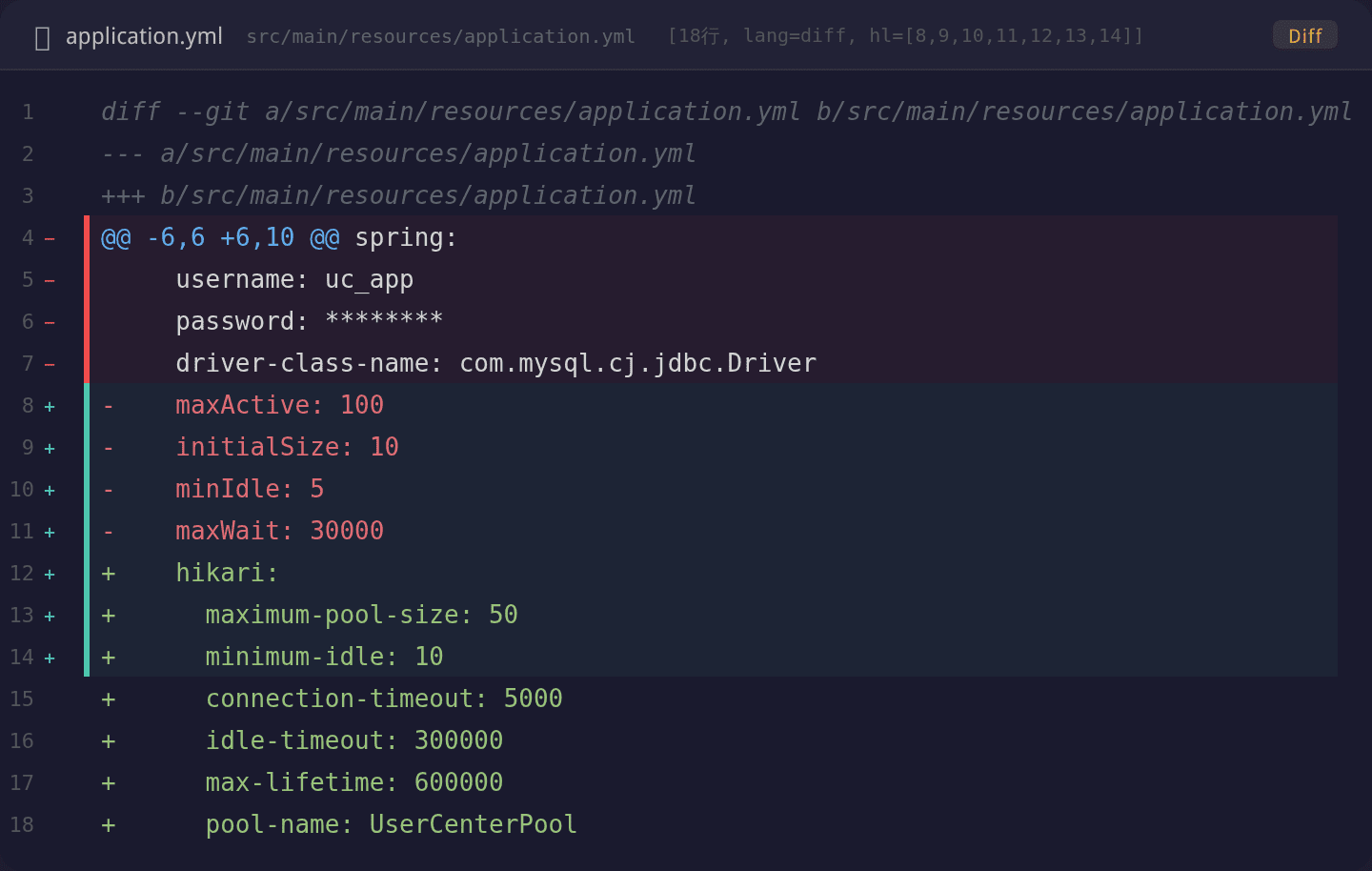
关键改动:
| 操作 | 参数 | 旧值 | 新值 | 备注 |
|---|---|---|---|---|
| 删除 | maxActive |
100 | — | Druid 参数,HikariCP 不识别 |
| 删除 | initialSize |
10 | — | 同上 |
| 删除 | minIdle |
5 | — | 同上 |
| 删除 | maxWait |
30000 | — | 同上 |
| 新增 | maximumPoolSize |
— | 50 | HikariCP 正确参数 |
| 新增 | connectionTimeout |
— | 5000 | 从默认 30s 改为 5s,快速失败 |
| 新增 | minimumIdle |
— | 10 | 保留空闲保活 |
添加连接池监控端点
部署后需要一个接口随时查看连接池状态:
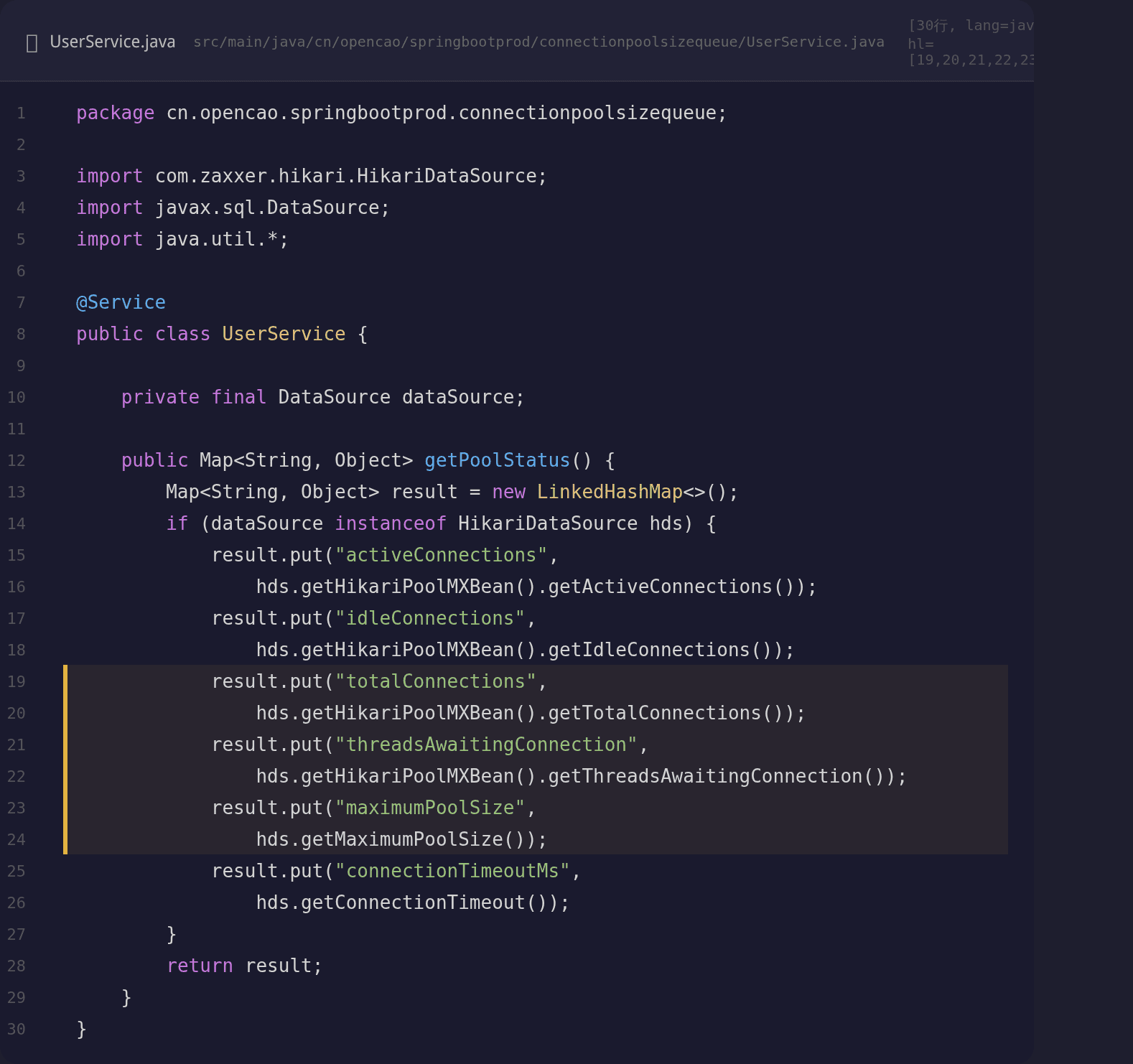
if (dataSource instanceof HikariDataSource hds) {
result.put("activeConnections",
hds.getHikariPoolMXBean().getActiveConnections());
result.put("idleConnections",
hds.getHikariPoolMXBean().getIdleConnections());
result.put("totalConnections",
hds.getHikariPoolMXBean().getTotalConnections());
result.put("threadsAwaitingConnection",
hds.getHikariPoolMXBean().getThreadsAwaitingConnection());
}
验证结果
部署 v2 后,连接池恢复正常:
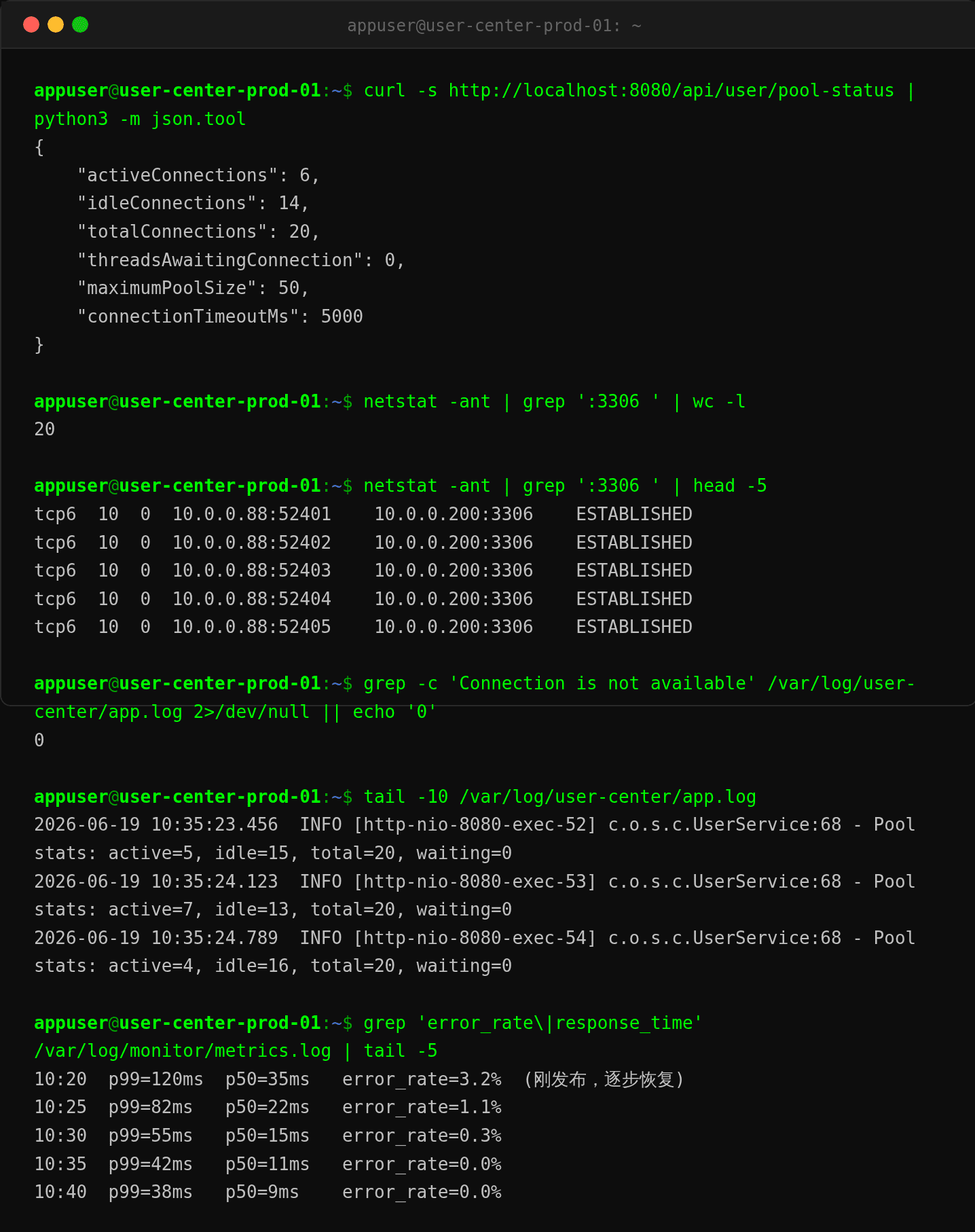
{
"activeConnections": 6,
"idleConnections": 14,
"totalConnections": 20,
"threadsAwaitingConnection": 0,
"maximumPoolSize": 50,
"connectionTimeoutMs": 5000
}
activeConnections从 10 降到 6(不再打满)threadsAwaitingConnection从 63 降到 0(无排队)- p99 响应从 5.8s 降到 38ms
- 错误率从 8.1% 降到 0%
避坑建议
1. 迁移连接池 = 改两个文件
从 Druid 切到 HikariCP 不只是改 pom.xml:
✅ pom.xml: 移除 Druid 依赖 → 加上 spring-boot-starter-jdbc
✅ application.yml: 删除 Druid 参数 → 添加 HikariCP 参数
缺一不可。建议迁移完成后 grep -E 'maxActive|initialSize|filters|Druid' application.yml 确认无残留。
2. HikariCP 对陌生参数静默忽略
这是最坑的地方。Druid 的 maxActive、initialSize、minIdle 等参数配置在 spring.datasource.* 下,HikariCP 启动时不报错、不警告,直接走默认值。如果没有连接池监控,你根本不知道参数没生效。
3. connectionTimeout 不要用默认 30s
30 秒超时意味着一场故障需要 30 秒才暴露。在这 30 秒内 Tomcat 线程全在等连接,前端重试加剧雪崩。建议 3-5 秒,快速失败比缓慢窒息好。
4. 连接池必须配监控
加一个 /api/user/pool-status 端点暴露 HikariPoolMXBean,随时可以看:
- threadsAwaitingConnection > 0 是连接池告警的核心指标
- activeConnections 接近 maximumPoolSize 说明要扩了
5. 配置文件 review 纳入迁移流程
这次事故的核心是 配置文件和依赖不同步。团队流程里加一个检查点:改 pom.xml 后必须审计 application.yml 中对应的配置参数。
附:完整命令清单
系统排查
top -b -n 1 | head -25 # 系统资源概览
netstat -ant | grep ':3306 ' # 查看 MySQL 连接
ss -ant 'sport = :3306 or dport = :3306' # 同上(更快)
awk '{print $6}' | sort | uniq -c | sort -rn # 连接状态统计
iostat -x 1 3 # IO 状况
应用日志排查
tail -200 app.log | grep -E 'ERROR|Connection|hikari' | head -25
grep -c 'Connection is not available' app.log
grep 'Connection is not available' app.log | awk -F'[:,]' '{print $NF}' | sort | uniq -c | sort -rn
连接池配置审计
grep -rn 'maxActive\|initialSize\|minIdle\|filters' src/main/resources/ # 检查 Druid 残留
grep -rn 'hikari\|maximumPoolSize\|connectionTimeout' src/main/resources/ # 检查 HikariCP 配置
连接池运行时状态
curl -s http://localhost:8080/api/user/pool-status | python3 -m json.tool
Git 排查迁移历史
git log --oneline --all --grep='druid\|Druid\|datasource\|连接池'
git show <commit>:pom.xml | grep -E 'druid|hikari|jdbc'
📖 完整版带可复现 Demo → opencao.cn 📺 公众号「Ai拆代码的曹操」 🌟 知识星球「源阅会」(82877104)


