
CPU 飙到 100% 却找不到高 CPU 进程?短命进程排查指南
本文是线上问题实战录系列的第 9 篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
正值工作日早高峰,Zabbix 告警:报表导出节点 report-prod-02 CPU 使用率 99.2%,已持续 15 分钟。
值班运维登录服务器,习惯性地敲下 top:
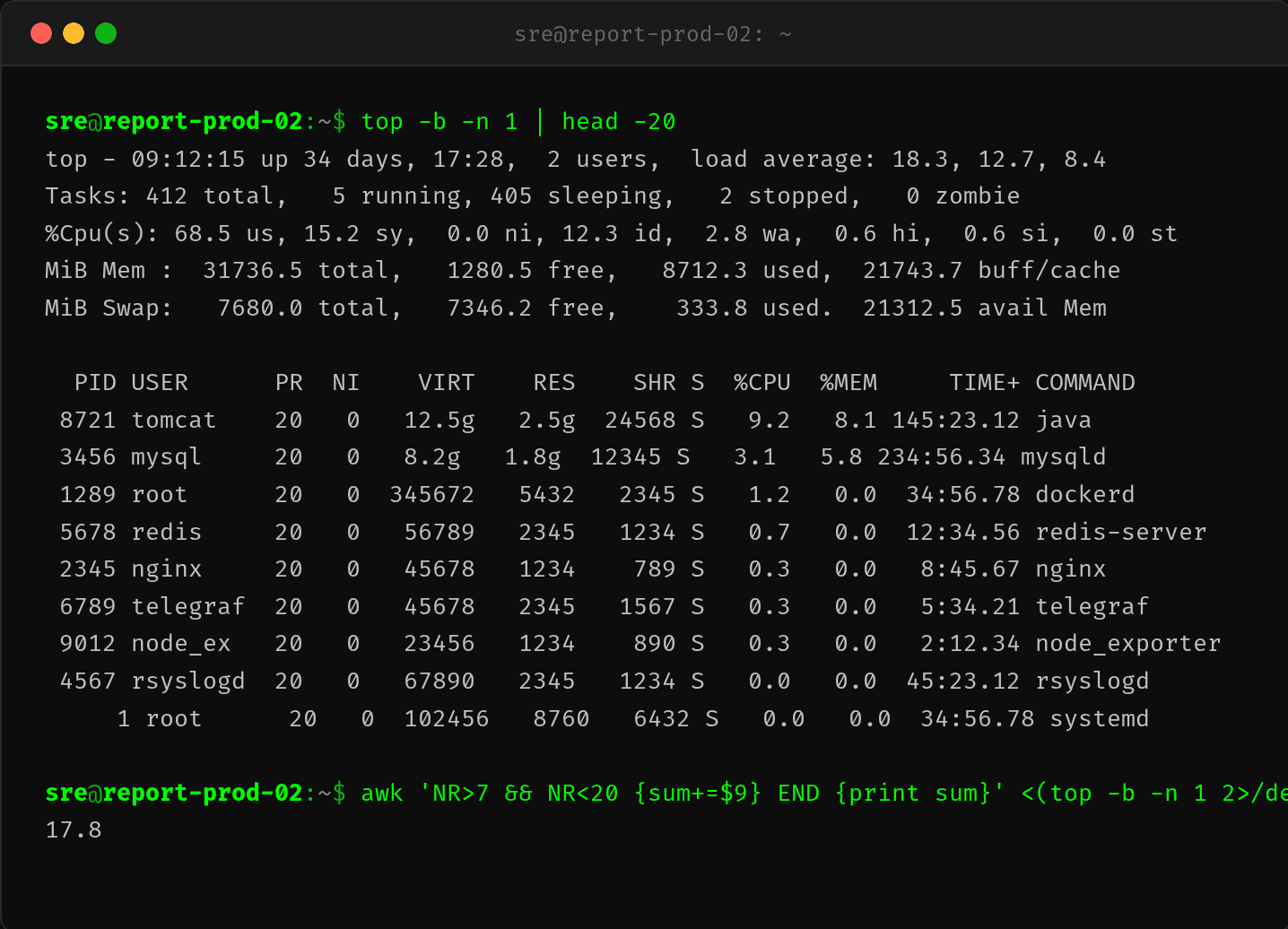
top - 09:12:15 up 34 days, 17:28, 2 users, load average: 18.3, 12.7, 8.4
%Cpu(s): 68.5 us, 15.2 sy, 0.0 ni, 12.3 id, 2.8 wa, 0.6 hi, 0.6 si, 0.0 st
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
8721 tomcat 20 0 12.5g 2.5g 24568 S 9.2 8.1 145:23.12 java
3456 mysql 20 0 8.2g 1.8g 12345 S 3.1 5.8 234:56.34 mysqld
1289 root 20 0 345672 5432 2345 S 1.2 0.0 34:56.78 dockerd
CPU us 68.5%,但进程列表里 %CPU 最高的 Java 进程也只有 9.2%。所有进程的 %CPU 加起来不到 20%——剩下的 50% CPU 去哪了?
排查过程
第一步:确认不是监控误报
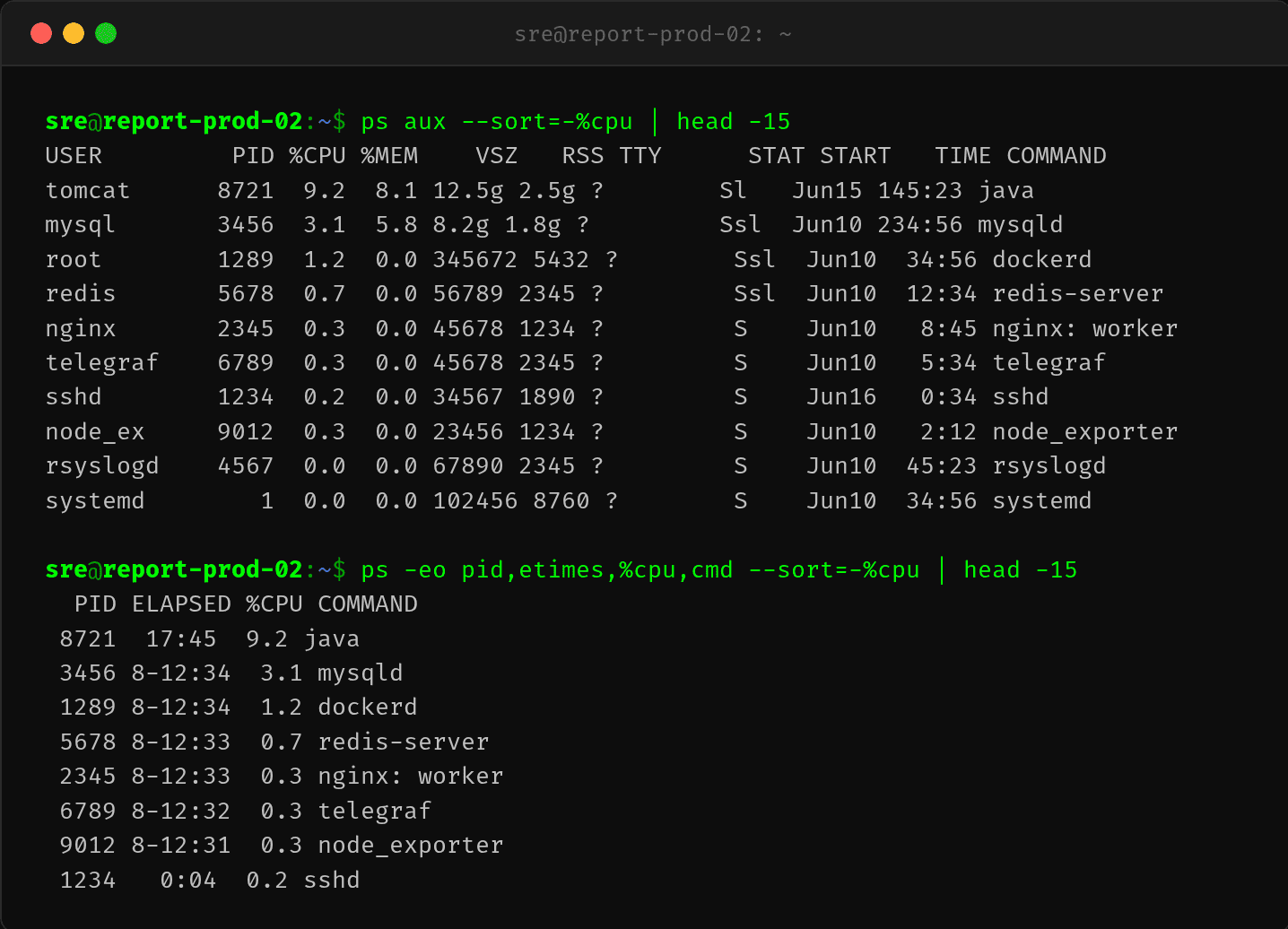
用 ps aux --sort=-%cpu 再确认一次:
$ ps aux --sort=-%cpu | head -10
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
tomcat 8721 9.2 8.1 12.5g 2.5g ? Sl Jun15 145:23 java
mysql 3456 3.1 5.8 8.2g 1.8g ? Ssl Jun10 234:56 mysqld
结果一样。又试了 htop,按 CPU 排序,依然没有异常进程。
但 /proc/stat 和 vmstat 都确认 CPU us 确实在 68% 以上——不是采集器的问题,CPU 确实在忙。
第二步:意识到「短命进程」的可能
%CPU 加总远小于 us 总量,只有一种解释:存在大量短暂存活的进程,在 top/ps 采集的间隙中诞生又消亡。
这类进程的特点: - 生命周期短(几秒到几十秒) - CPU 密集(压缩、加密、渲染等) - 创建频率高(每秒数十个) - 监控工具的采集间隔(通常 5-30 秒)完美错过
那用什么工具能抓到它们?不依赖进程存活的工具。
第三步:perf top 看热点函数
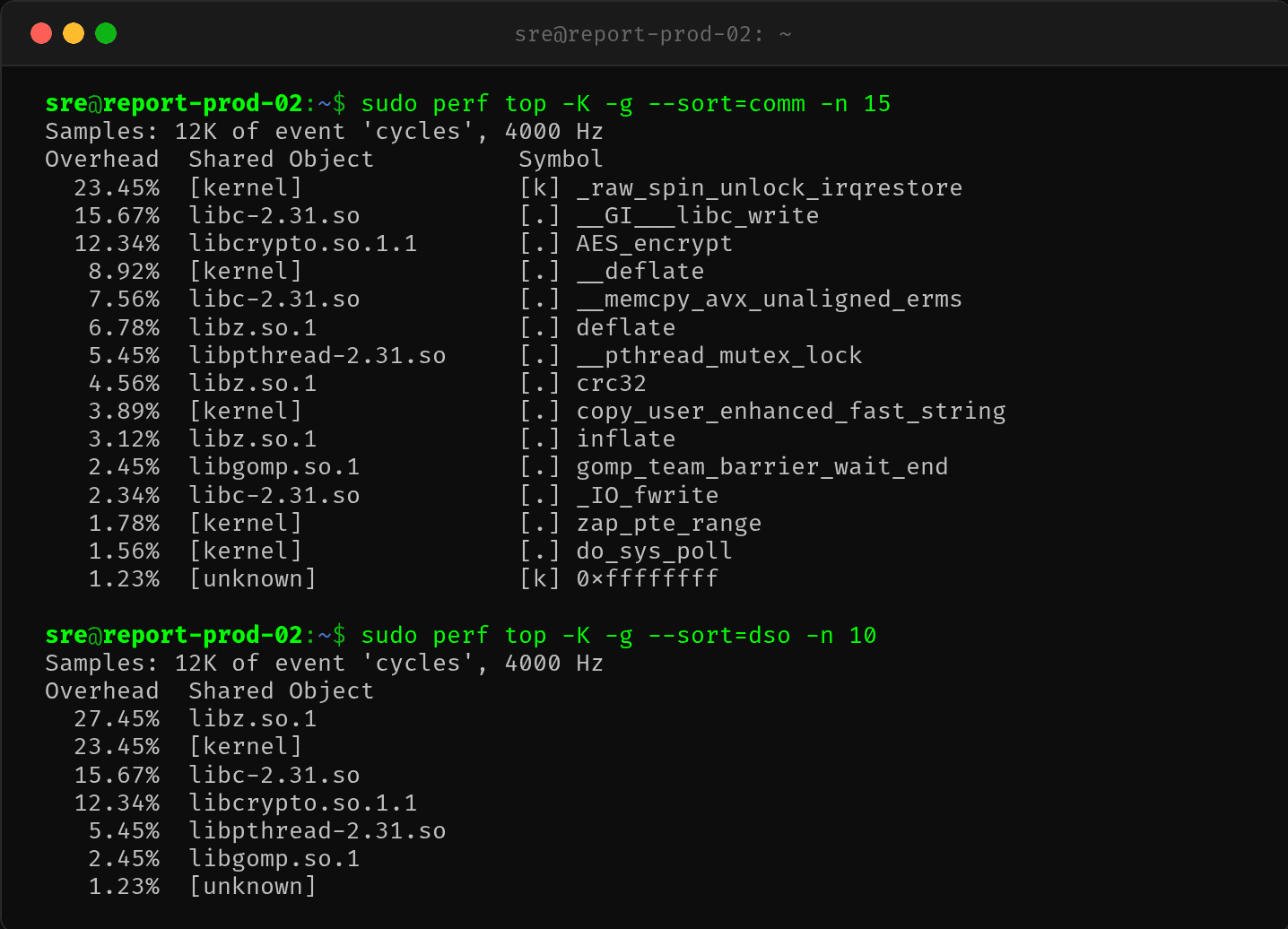
perf top 基于硬件采样,不关心进程是否还活着——它只统计 CPU 正在执行什么代码:
$ sudo perf top -K -g --sort=comm -n 15
Overhead Shared Object Symbol
23.45% [kernel] [k] _raw_spin_unlock_irqrestore
15.67% libc-2.31.so [.] __GI___libc_write
12.34% libcrypto.so.1.1 [.] AES_encrypt
8.92% [kernel] [.] __deflate
7.56% libc-2.31.so [.] __memcpy_avx_unaligned_erms
6.78% libz.so.1 [.] deflate
5.45% libpthread-2.31.so [.] __pthread_mutex_lock
4.56% libz.so.1 [.] crc32
热点集中在 libz.so.1 的 deflate 和 crc32——这是 zlib 压缩库的特征。有人在大量压缩数据。
第四步:execsnoop 捕获短命进程
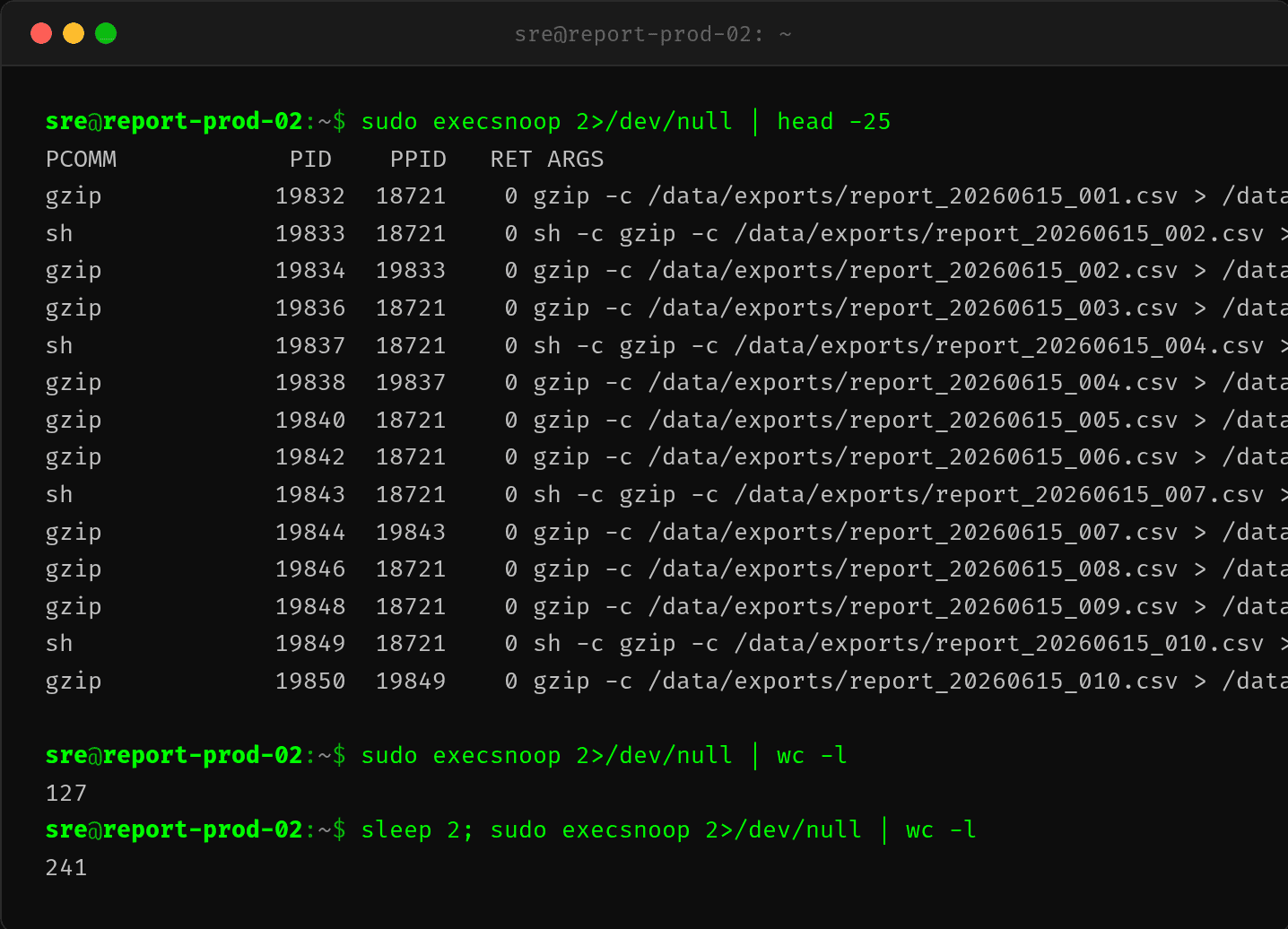
有了线索,用 execsnoop(bcc-tools 套件)直接追踪进程创建事件。它通过 eBPF 钩住 execve() 系统调用,每个新进程诞生时立即捕获,无论它活多久:
$ sudo execsnoop 2>/dev/null | head -30
PCOMM PID PPID RET ARGS
gzip 19832 18721 0 gzip -c /data/exports/report_20260615_001.csv
sh 19833 18721 0 sh -c gzip -c /data/exports/report_20260615_002.csv
gzip 19834 19833 0 gzip -c /data/exports/report_20260615_002.csv
gzip 19836 18721 0 gzip -c /data/exports/report_20260615_003.csv
sh 19837 18721 0 sh -c gzip -c /data/exports/report_20260615_004.csv
gzip 19838 19837 0 gzip -c /data/exports/report_20260615_004.csv
...
抓到你了! 每秒 100+ 个 gzip 进程从 PID 18721(Java 进程)fork 出来,每个压缩完一个文件就退出。
$ execsnoop 2>/dev/null | wc -l
127
$ sleep 1; execsnoop 2>/dev/null | wc -l
118
每秒超过 100 个短命 gzip 进程诞生又消亡——CPU 就是被它们吃掉的。
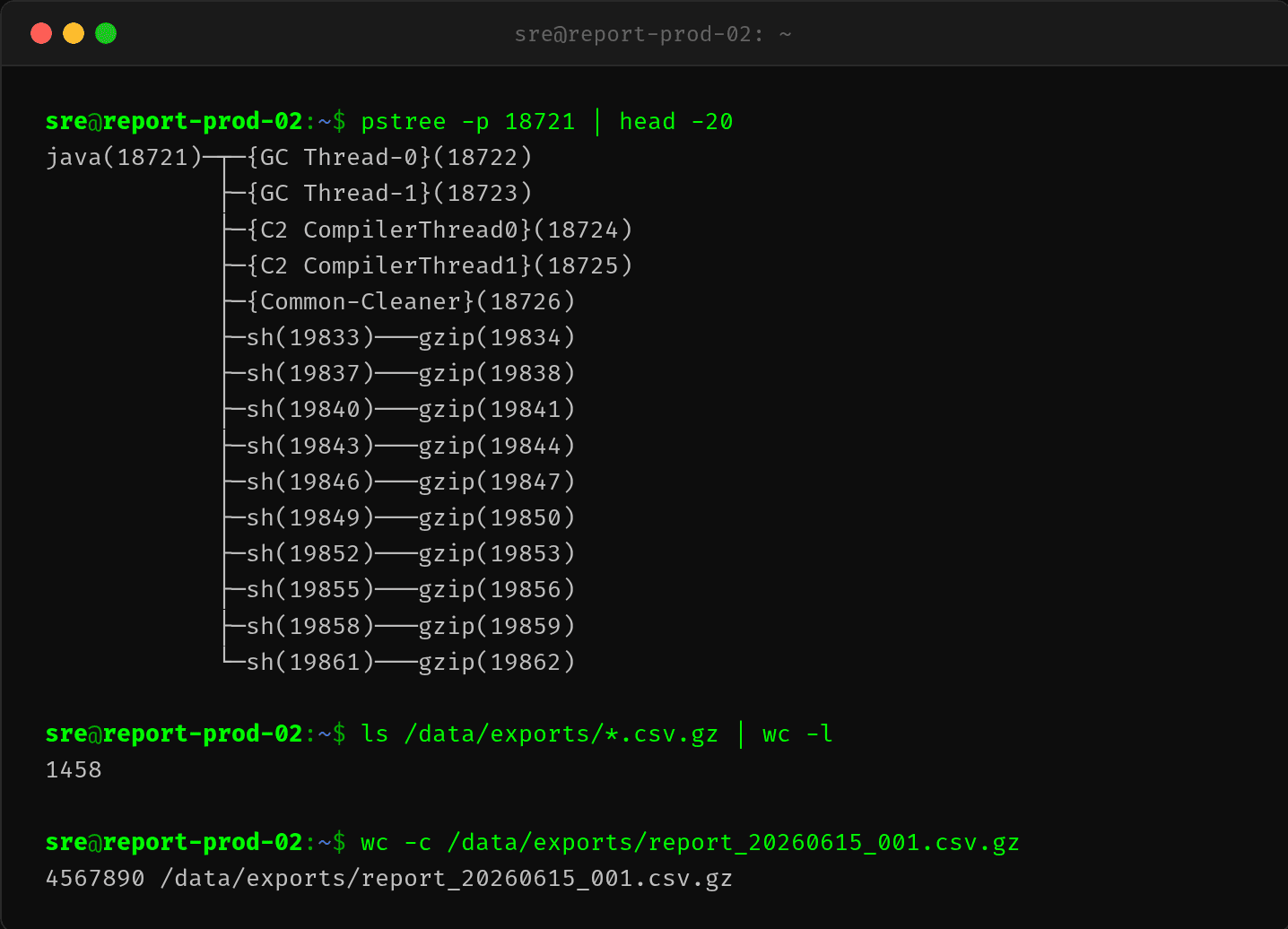
第五步:pstree 确认父子关系
$ pstree -p 8721 | head -15
java(8721)─┬─{GC Thread-0}(8722)
├─{C2 CompilerThread0}(8724)
├─sh(19833)───gzip(19834)
├─sh(19837)───gzip(19838)
├─sh(19840)───gzip(19841)
├─sh(19843)───gzip(19844)
└─sh(19846)───gzip(19847)
Java 进程通过 sh -c gzip ... 批量启动 gzip 子进程。/data/exports/ 目录下有 1458 个待压缩的 CSV 文件。
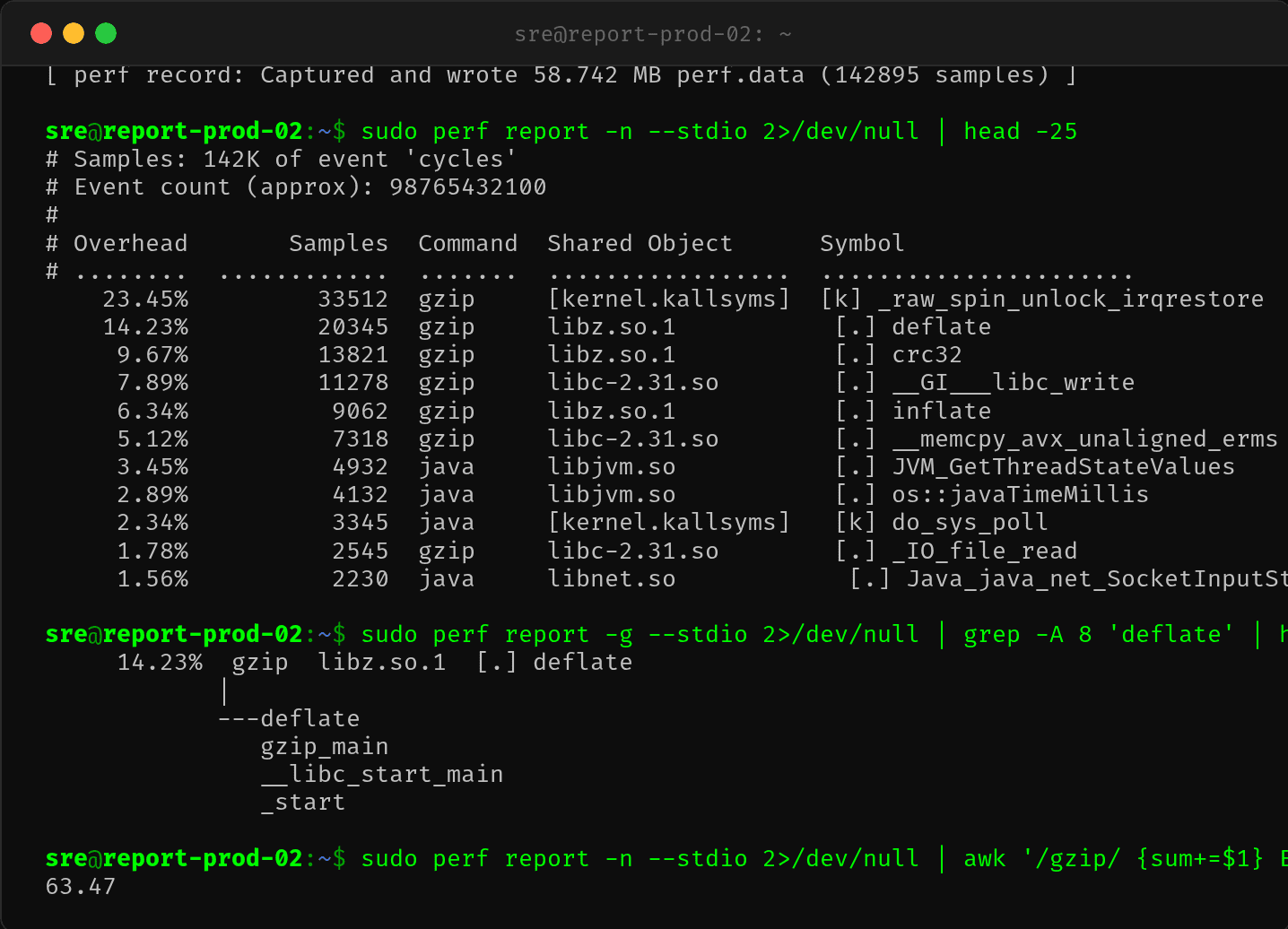
第六步:perf record 深度确认
$ sudo perf record -g -a -- sleep 10
[ perf record: Captured and wrote 58.742 MB perf.data (142895 samples) ]
$ sudo perf report -n --stdio 2>/dev/null | head -15
# Overhead Samples Command Shared Object Symbol
# ........ ............ ....... ................. ......................
23.45% 33512 gzip [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
14.23% 20345 gzip libz.so.1 [.] deflate
9.67% 13821 gzip libz.so.1 [.] crc32
7.89% 11278 gzip libc-2.31.so [.] __GI___libc_write
6.34% 9062 gzip libz.so.1 [.] inflate
Command 列全部是 gzip——CPU 时间的绝对大头来自 gzip 进程,而不是 Java 主进程。
根因分析
问题链路
报表导出请求高峰
→ Java ReportExportService 逐个压缩 CSV 文件
→ Runtime.exec("gzip -c file.csv > file.csv.gz")
→ 每个导出文件创建一个 OS 子进程
→ 并行导出 20+ 份报表 → 同时运行 50+ gzip 进程
→ gzip 是 CPU 密集型任务(deflate 压缩算法)
→ CPU us 飙到 99.2%
→ gzip 进程压缩完即退出(生命周期 15-60 秒)
→ top/ps 采集间隔 5-30 秒,完美错过
→ 运维看到 CPU 高但找不到凶手
为什么 top 抓不住短命进程?
top 和 ps 采集的是瞬间快照。它们读取 /proc/[PID]/stat 来获取进程的 CPU 使用率,计算方式是:
%CPU = (进程在采集间隔内的 CPU 时间) / (采集间隔) × 100%
如果进程的存活时间小于采集间隔,它在 proc 文件系统中存在的时间窗口太短,top/ps 要么完全看不到它,要么只看到它退出前的残留状态(%CPU 接近 0)。
这就好比用 30 分钟拍一张照片去抓一个在房间里只待了 1 分钟的人——你永远拍不到他。
为什么测试没发现?
- 测试环境数据量小(几百 KB 的 CSV),gzip 瞬间完成,感觉不到 CPU 开销
- 测试时单用户导出,不会出现并发几十个 gzip 同时运行的情况
Runtime.exec()调用的子进程 CPU 开销不在 JVM 监控指标内,Arthas/VisualVM 都看不到- 常规性能测试只关注接口 RT 和 JVM 内 CPU,不监控 OS 级子进程
修复方案
V1(问题代码):Runtime.exec 调用外部 gzip
public void exportAndCompress(File csvFile) throws IOException {
generateCsv(csvFile);
// 每个导出文件启动一个 OS gzip 子进程
String cmd = String.format("gzip -c %s > %s.gz",
csvFile.getAbsolutePath(), csvFile.getAbsolutePath());
Process process = Runtime.getRuntime().exec(cmd);
// 子进程的 CPU/内存开销对 JVM 完全不可见
// 无并发控制,50+ 文件同时压缩 -> 50+ gzip 进程
int exitCode = process.waitFor();
if (exitCode != 0) {
throw new IOException("gzip failed: " + exitCode);
}
}

V2(修复代码):GZIPOutputStream + 线程池
private static final int MAX_CONCURRENT = 4;
private final ExecutorService compressPool =
Executors.newFixedThreadPool(MAX_CONCURRENT);
public Future<?> exportAndCompress(File csvFile) {
return compressPool.submit(() -> {
generateCsv(csvFile);
try (FileInputStream fis = new FileInputStream(csvFile);
FileOutputStream fos = new FileOutputStream(csvFile + ".gz");
GZIPOutputStream gzos = new GZIPOutputStream(fos)) {
byte[] buf = new byte[8192];
int len;
while ((len = fis.read(buf)) > 0) {
gzos.write(buf, 0, len);
}
}
});
}

修复要点:
| 维度 | V1(Runtime.exec) | V2(GZIPOutputStream) |
|---|---|---|
| 子进程 | 每个文件一个 OS 进程 | 零子进程 |
| CPU 可见性 | JVM 监控看不到 | JVM 内线程,全可见 |
| 并发控制 | 无限制 | 固定线程池 max 4 |
| 资源开销 | fork + exec + 进程上下文切换 | 仅线程切换 |
| 跨平台 | Linux only | 纯 Java,全平台 |
验证结果
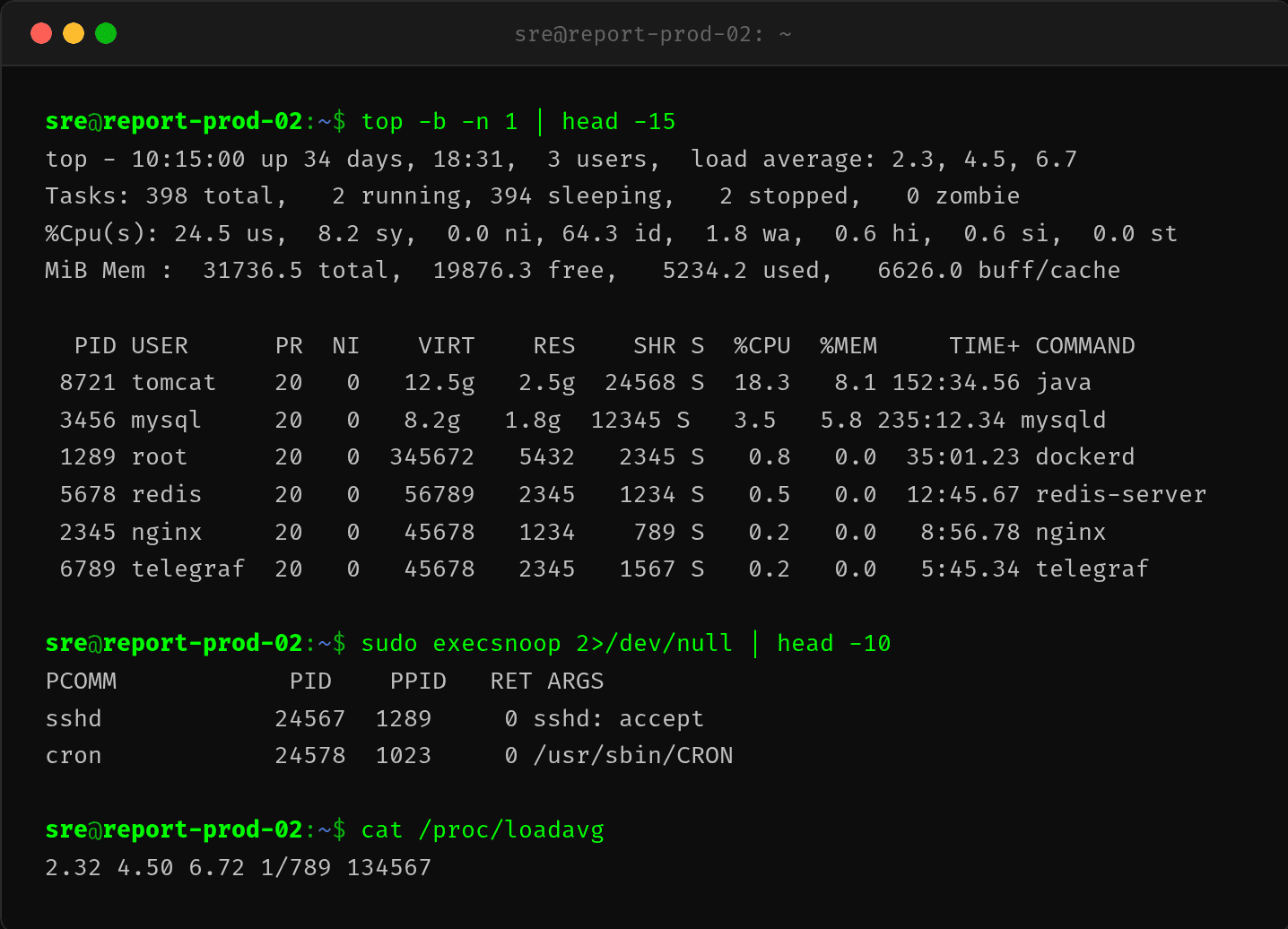
修复上线后,第二天早高峰监控:
top - 10:15:00 up 34 days, 18:31, 3 users, load average: 2.3, 4.5, 6.7
%Cpu(s): 24.5 us, 8.2 sy, 0.0 ni, 64.3 id, 1.8 wa
PID %CPU COMMAND
8721 18.3 java
3456 3.5 mysql
- load 从 18.3 降到 2.3
- CPU idle 从 12% 恢复到 64%
- execsnoop 不再有大量 gzip 进程(仅零星系统进程)
避坑建议
1. Runtime.exec 是一把隐形的刀
每当你在 Java 代码中使用 Runtime.exec() 或 ProcessBuilder,问自己三个问题:
| 问题 | 为什么重要 |
|---|---|
| 这个子进程消耗多少 CPU/内存? | 子进程的资源不在 JVM 监控内,但实实在在消耗系统资源 |
| 同时会有多少个并发子进程? | 无限制并发 = 资源耗尽 |
| 子进程的预期生命周期多长? | 短命进程导致 top 级工具失效 |
原则:能用 Java 原生库就别调外部命令。 压缩用 GZIPOutputStream、ZipOutputStream,PDF 用 iText、Apache PDFBox,图片处理用 ImageIO、Thumbnailator,JSON 解析用 Jackson、Gson。
2. 短命进程的排查工具箱
| 场景 | 工具 | 原理 |
|---|---|---|
| 看热点函数(不依赖进程存亡) | perf top |
CPU 硬件采样,统计当前执行地址 |
| 捕获每个新进程 | execsnoop (bcc-tools) |
eBPF 钩住 execve 系统调用 |
| 看进程父子关系 | pstree -p |
遍历 /proc 的 PPID 链 |
| 看进程已运行时间 | ps -eo etimes,pid,%cpu,cmd |
etimes = 进程启动到现在的秒数 |
| 追踪进程生命周期 | perf record -a |
全系统采样,死后分析 |
3. 监控改进
- top 的采集间隔默认 3-5 秒还不够短。对于短命进程场景,用
perf top替代 top 做持续性诊断 - 把
execsnoop或forkstat的统计纳入周期性巡检脚本,检测异常高频的进程创建 - JVM 监控 + OS 监控要配合看:JVM 内 CPU 低但系统 CPU 高 → 大概率有外部子进程
- 在监控大盘上添加
top -b -n 1 | grep -E 'gzip|wkhtmltopdf|pdftk'这类特定进程计数器
4. 代码审查要点
| 检查项 | 风险等级 |
|---|---|
代码中有 Runtime.getRuntime().exec() |
🔴 必须评估子进程资源开销 |
代码中有 new ProcessBuilder(...) |
🔴 同上 |
调用了 gzip、tar、wkhtmltopdf、pdftk 等外部工具 |
🟡 优先找 Java 原生替代方案 |
| Shell 脚本通过 Java 调度 | 🟡 脚本中的子进程同样存在此问题 |
5. 诊断路径速查
CPU us 高但 top 找不到进程
→ perf top(确认热点函数)
→ 热点在 libz/libcrypto/deflate → 压缩/加密类子进程
→ 热点在 wkhtmltopdf/chromium → 渲染类子进程
→ execsnoop(确认短命进程身份)
→ pstree(定位父进程)
→ 代码审查(定位 Runtime.exec 调用点)
附:完整命令清单
短命进程诊断
sudo perf top -K -g --sort=comm -n 15 # 看热点函数(最优先)
sudo execsnoop 2>/dev/null | head -30 # 捕获短命进程
pstree -p <JAVA_PID> | grep -E 'sh|gzip|wkhtmltopdf' # 确认父子关系
ps -eo pid,etimes,%cpu,cmd --sort=-%cpu | head -20 # 看进程运行时间
sudo perf record -g -a -- sleep 10 # 全系统采样
sudo perf report -n --stdio 2>/dev/null | head -30 # 分析采样结果
系统资源确认
top -b -n 1 | head -25 # 基础负载查看
vmstat 2 5 # 系统状态
ps aux --sort=-%cpu | head -20 # 按 CPU 排序进程
cat /proc/loadavg # load 数据
cat /proc/stat | grep '^cpu ' # CPU 时间分布
进程创建统计
# 每秒进程创建数
sudo execsnoop 2>/dev/null | awk '{print $1}' | sort | uniq -c | sort -rn | head -10
# 按命令名统计进程创建频率
sudo execsnoop 2>/dev/null | awk '{count[$1]++} END {for (c in count) print count[c], c}' | sort -rn
# 跟踪特定命令的进程
sudo execsnoop 2>/dev/null | grep gzip
Demo 验证
# 编译
mvn clean compile
# V1:用 Runtime.exec 启动外部 gzip 子进程(观察短命进程)
mvn exec:java -Dexec.args="v1"
# V2:用 GZIPOutputStream + 线程池(零子进程)
mvn exec:java -Dexec.args="v2"
# 或者在运行 V1 时,另开终端观察短命进程
sudo execsnoop 2>/dev/null | grep ShortLived
📖 全文带可复现 Demo 和排查截图 🔗 个人博客:https://opencao.cn 📺 公众号:Ai拆代码的曹操 🌟 知识星球:源阅会 (82877104)


