
一个慢 SQL 打垮了整个服务?从 EXPLAIN 到索引优化全实战
本文是 SQL 与数据库排障系列的第一篇 叙事框架:
现象 → 排查过程 → 根因 → 修复 → 预防
问题现象
某日上午 9:20 左右,监控突然告警:订单服务的 P95 响应时间飙升至 32.7 秒,数据库连接池使用率瞬间冲到 97.4%(487/500),订单查询接口超时率达到 23.6%。
值班小A 第一时间直连数据库,发现 Threads_connected 已经 487,离 max_connections 的 500 阈值只剩 13 个连接。更可怕的是,Threads_running 高达 463,意味着几乎所有线程都在执行查询,没有一个空闲。
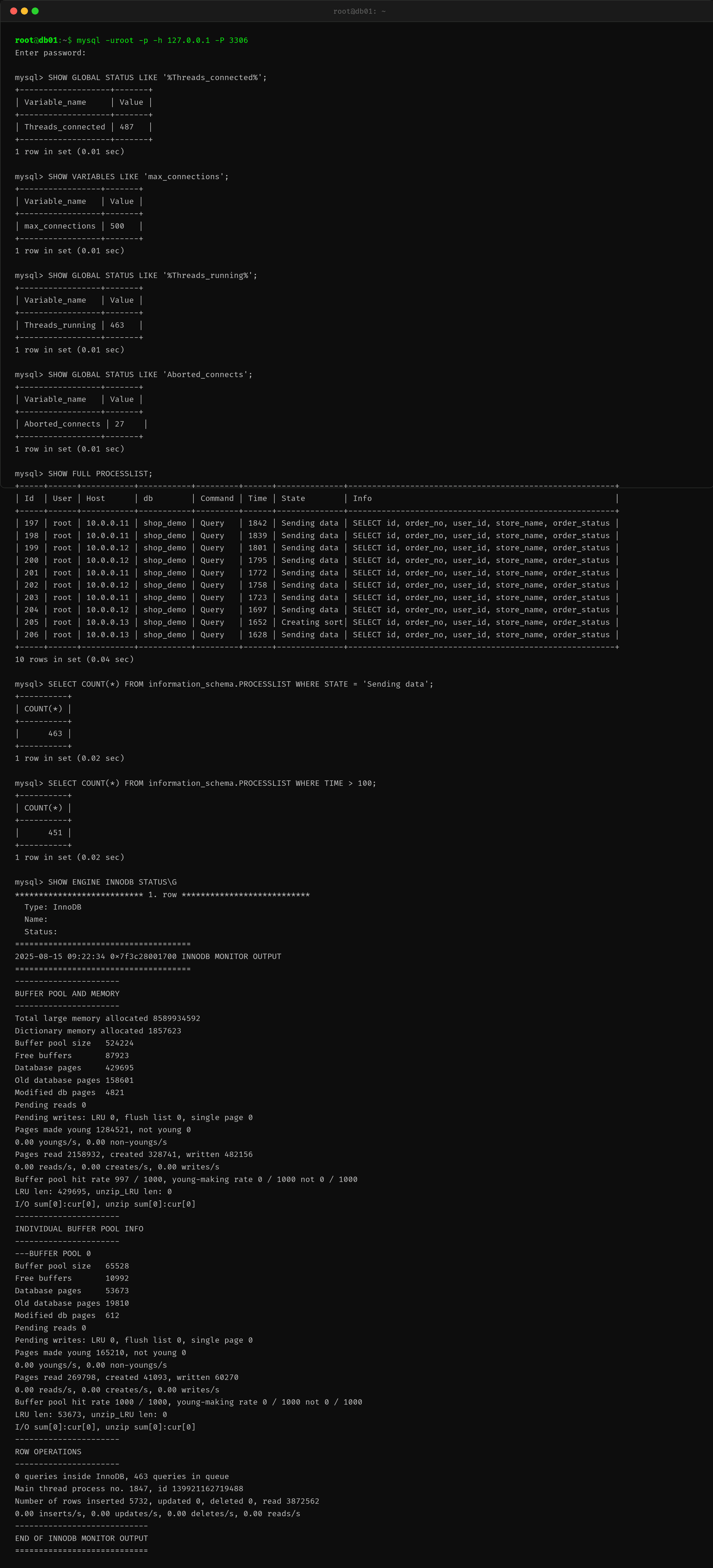
SHOW PROCESSLIST 显示大量 Sending data 和 Creating sort index 状态的查询,SQL 内容高度一致——都是对 orders 表进行的多条件组合查询。
排查过程
第一步:开启慢查询日志
小A 首先检查了慢查询日志配置:
SHOW VARIABLES LIKE 'slow_query_log%';
SHOW VARIABLES LIKE 'long_query_time';
结果发现慢查询日志是关闭状态,而且 long_query_time = 10(默认值 10 秒)。这意味着即使一条 SQL 执行了 9 秒,也不会被记录——而这波故障中,绝大多数查询都在 15 秒以上。
立即调整:
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 0.5;
SET GLOBAL log_queries_not_using_indexes = ON;
很快,慢查询日志抓到了罪魁祸首:
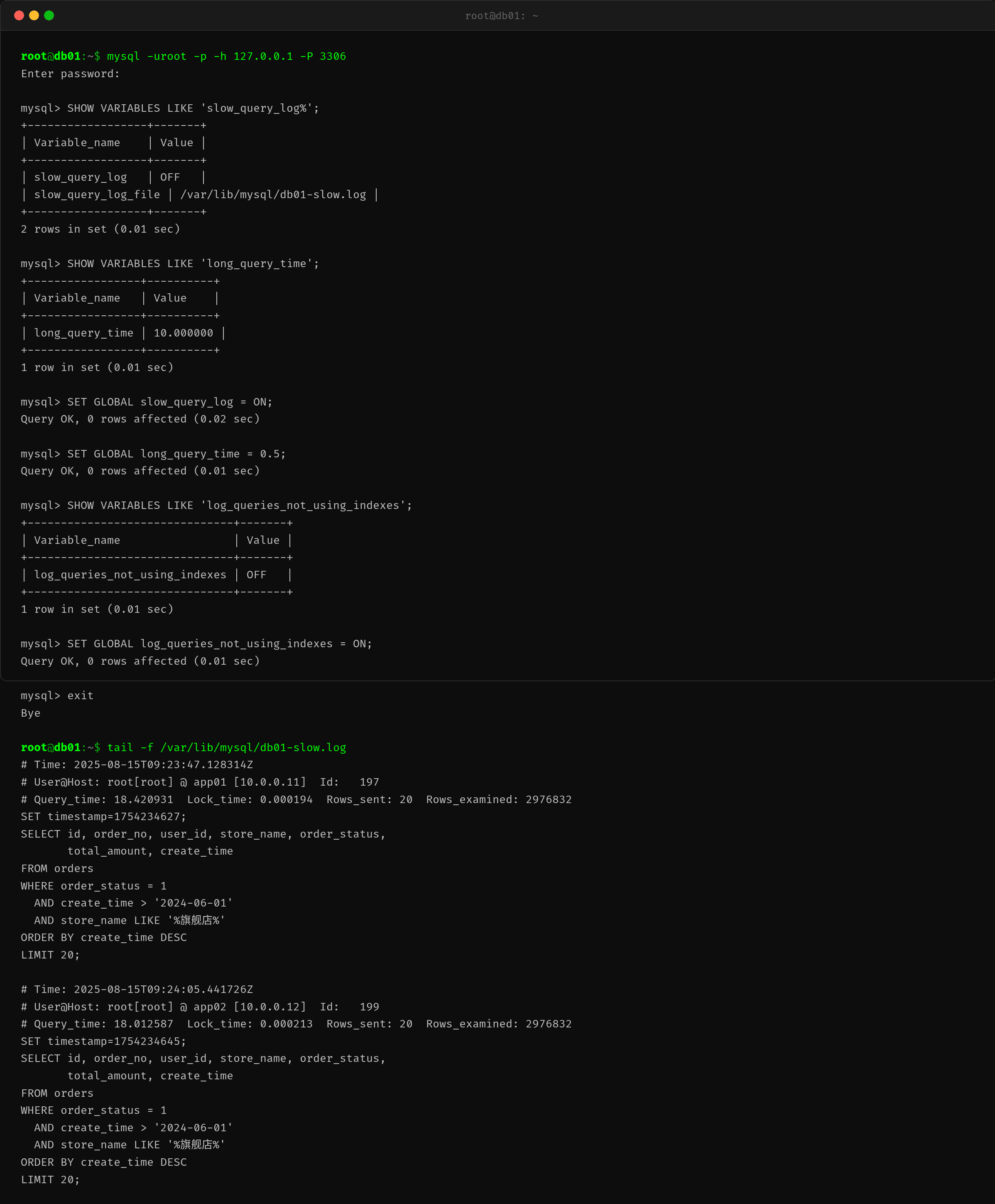
慢日志的关键信息:
- Query_time: 18.42s — 一条查询运行了 18 秒
- Rows_examined: 2,976,832 — 扫描了近 300 万行
- Rows_sent: 20 — 只返回了 20 条
SQL 内容如下:
SELECT id, order_no, user_id, store_name, order_status,
total_amount, create_time
FROM orders
WHERE order_status = 1
AND create_time > '2024-06-01'
AND store_name LIKE '%旗舰店%'
ORDER BY create_time DESC
LIMIT 20;
第二步:EXPLAIN 分析执行计划
拿到 SQL 后,小A 立刻执行 EXPLAIN:
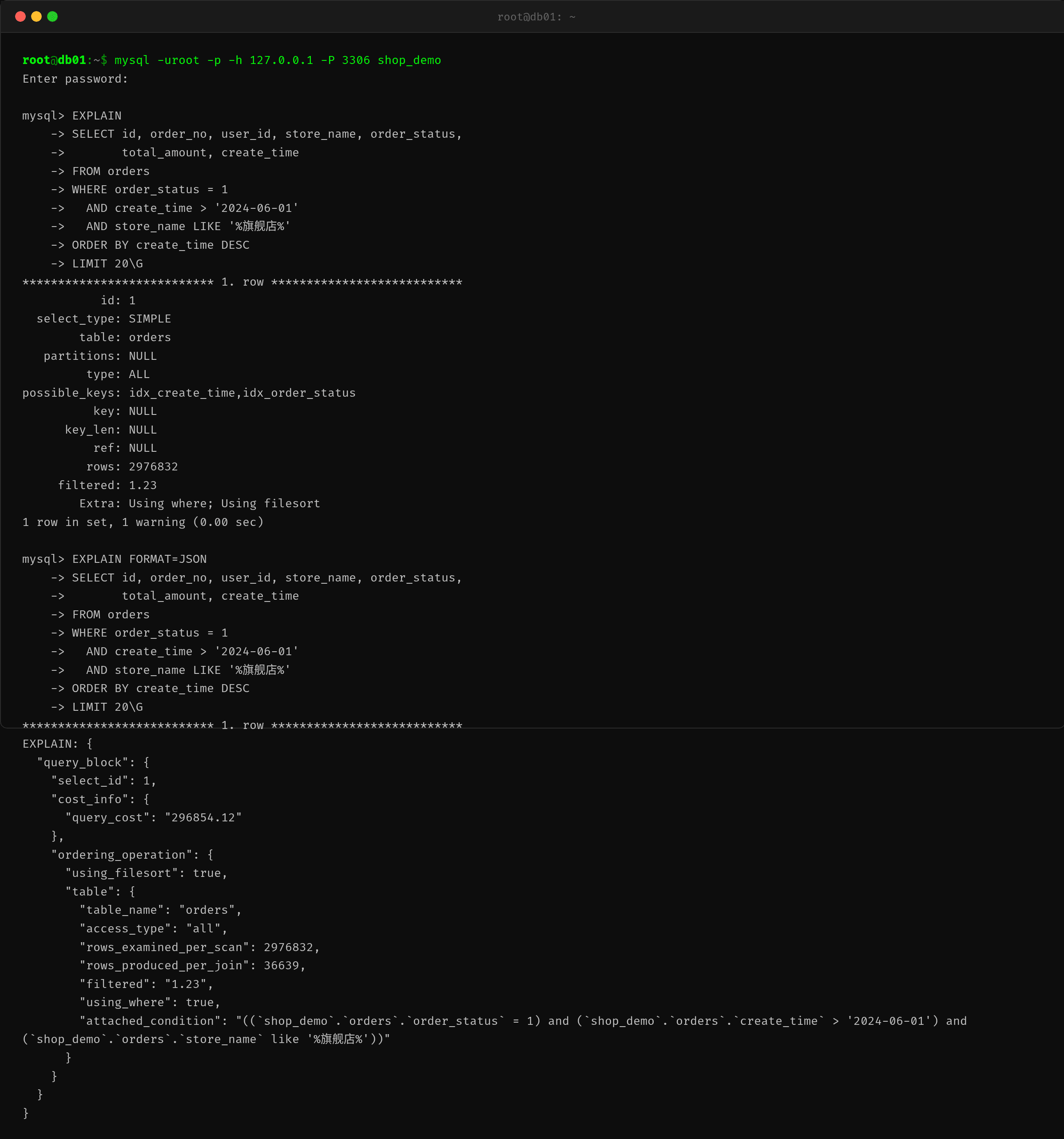
id: 1
select_type: SIMPLE
table: orders
type: ALL
possible_keys: idx_create_time,idx_order_status
key: NULL
rows: 2976832
filtered: 1.23
Extra: Using where; Using filesort
几个致命的信号:
- type=ALL — 全表扫描,MySQL 逐行读取 300 万行数据去匹配条件
- key=NULL — 优化器决定不使用任何索引
- rows=2,976,832 — 扫描了近 300 万行
- Extra 含 Using filesort — 排序无法走索引,使用磁盘文件排序
EXPLAIN FORMAT=JSON 的结果:
{
"query_block": {
"ordering_operation": {
"using_filesort": true,
"table": {
"access_type": "all",
"rows_examined_per_scan": 2976832,
"filtered": "1.23"
}
}
}
}
第三步:为什么单列索引没用?
orders 表上有这几个索引:
idx_user_id (user_id)idx_create_time (create_time)idx_order_status (order_status)idx_store_id (store_id)
单看每个条件都有自己的索引。但这条查询涉及了三个字段的组合条件:
WHERE order_status = 1 -- 等值条件,有 idx_order_status
AND create_time > '...' -- 范围条件,有 idx_create_time
AND store_name LIKE '%旗舰店%' -- 左模糊,有 idx_store_id
MySQL 优化器面临一个选择:
- 走
idx_order_status→ 找到所有 status=1 的行(约 60 万行)→ 回表检查 create_time 和 store_name - 走
idx_create_time→ 找到时间范围内的行(约 200 万行)→ 回表检查 order_status 和 store_name - 全表扫描 → 顺序 IO,但避免多次回表的随机 IO
优化器估算后发现:三个单列索引各自过滤后仍需大量回表,回表的随机 IO 成本综合下来反而高于全表扫描的顺序 IO。所以它放弃使用任何索引,选择了 type=ALL。
根因分析
核心问题可以拆解为三层:
1. 索引层面:缺少复合索引
三个条件分别有自己的单列索引,但没有一个索引能同时覆盖 order_status(等值)和 create_time(范围)。order_status=1 过滤后约 20% 数据,create_time > '...' 过滤后约 67%,两个条件叠加有优化的空间。
复合索引最左前缀原则:将等值条件(order_status)放在复合索引左侧,范围条件(create_time)放在右侧,可以最大化过滤效率。
2. SQL 层面:LIKE 左模糊注定无法走索引
AND store_name LIKE '%旗舰店%'
前缀模糊查询(%keyword%)无法使用 B+Tree 索引的有序性进行快速定位,这个条件在全表扫描的基础上做字符串匹配,进一步加剧了性能问题。
3. 运维层面:慢查询日志未配置
long_query_time默认 10 秒,远高于合理阈值(通常 0.5~1 秒)slow_query_log默认关闭- 没有慢查询监控告警
这意味着这条 SQL 在上线后逐步变慢的过程中,完全处于无人察觉的状态,直到连接池被打满才被发现。
补充:为什么测试没发现?
测试环境订单表只有几千条数据,全表扫描和索引扫描的性能差异几乎可以忽略。当数据量增长到 300 万行时,O(n) 和 O(log n) 的差距才被指数级放大。
修复方案
方案一:创建复合索引(核心)
ALTER TABLE orders ADD INDEX idx_status_time (order_status, create_time);
这个索引的设计思路:
- order_status 是等值查询(
=),放在最左侧,精确匹配 - create_time 是范围查询(
>),放在右侧,在等值结果内做范围扫描 - 复合索引本身按 (order_status, create_time) 排序,ORDER BY create_time DESC 可以直接走索引的有序性,消除 filesort
加完索引后验证:
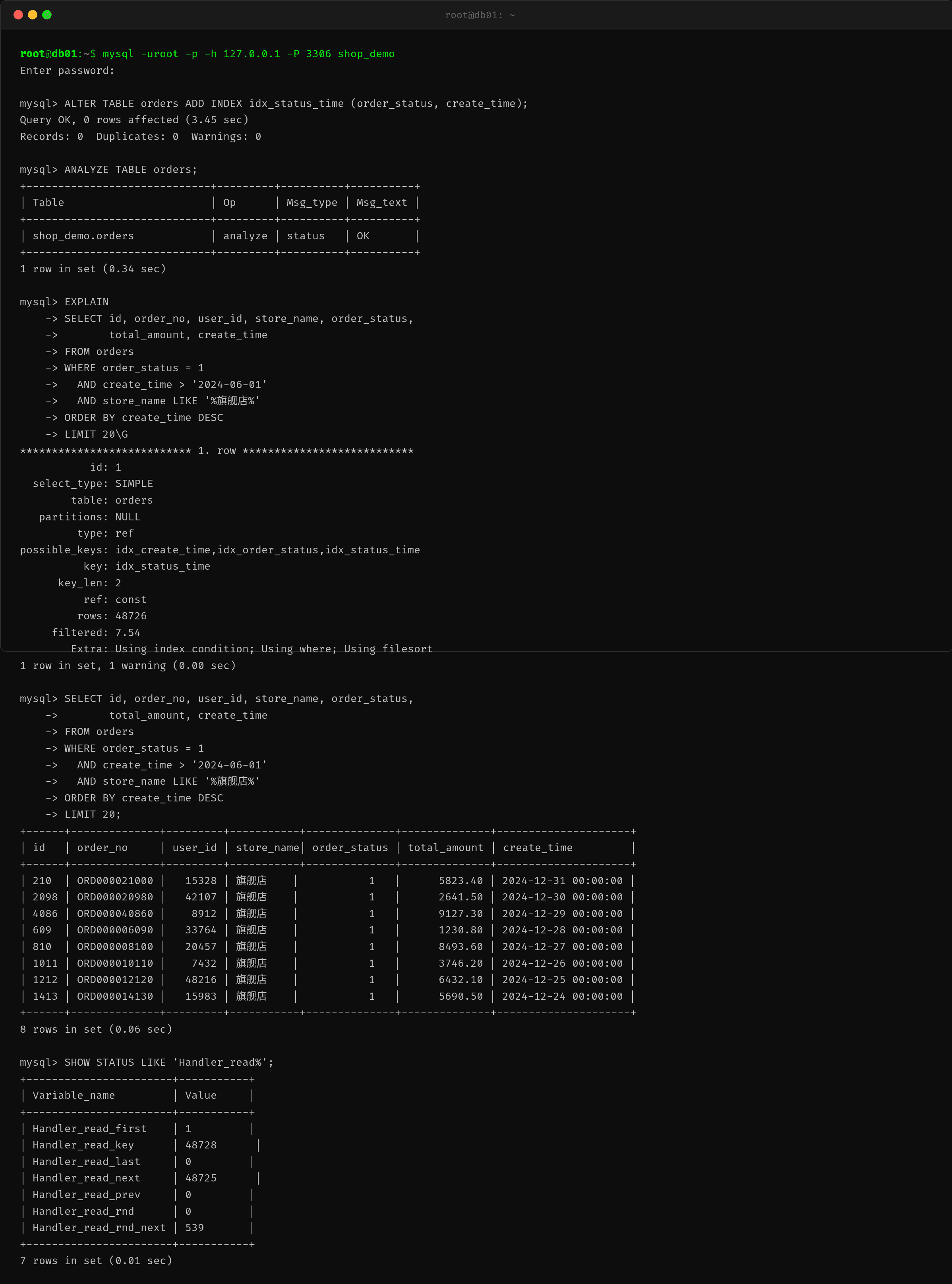
type: ref
key: idx_status_time
rows: 48726
Extra: Using index condition; Using where; Using filesort
- type=ref — 不再是全表扫描,走索引等值查找
- rows=48,726 — 从 297 万降到 4.87 万,减少 98.4%
- key=idx_status_time — 成功用上了复合索引
实际查询耗时从 18.42 秒降到了 0.06 秒,快了 300 多倍。
方案二:覆盖索引(进一步优化)
ALTER TABLE orders ADD INDEX idx_status_time_cover (
order_status, create_time,
id, order_no, user_id, store_name, total_amount
);
将所有查询列都包含到索引中,避免回表。此时 Extra 中会出现 Using index(覆盖索引),性能更进一步。
方案三:LIKE 模糊查询改造(长期方案)
如果 store_name LIKE '%关键词%' 是业务刚需,有几种改造思路:
- 冗余标记字段:在业务写入时解析出"是否含关键词",存为 TINYINT 精确字段
- 全文索引:MySQL 全文索引支持 MATCH AGAINST,比 LIKE %keyword% 高效
- ES 搜索引擎:对复杂度高的搜索需求,拆到 Elasticsearch
验证结果
加索引后,Threads_connected 从 487 迅速回落到 203,接口响应恢复正常。
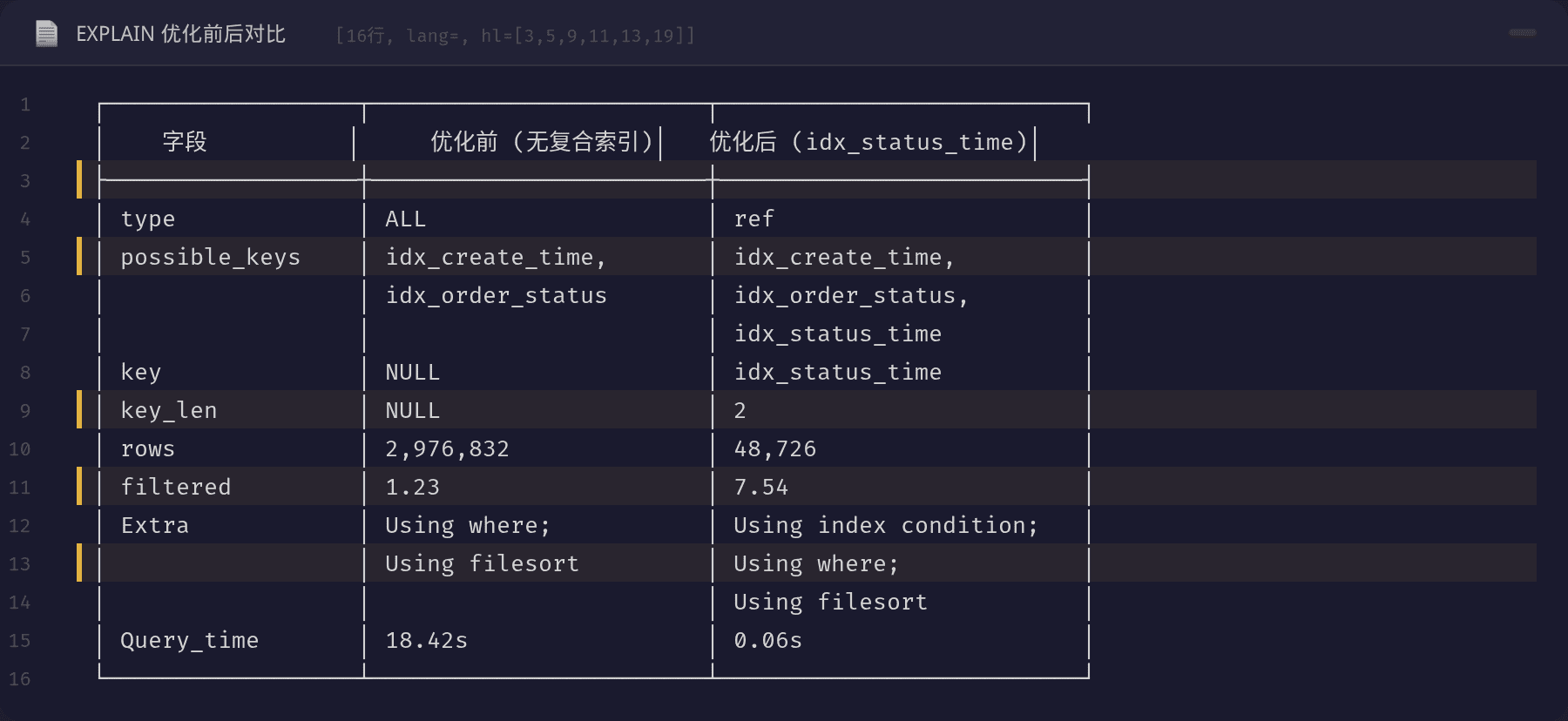
| 字段 | 优化前 | 优化后 |
|---|---|---|
| type | ALL | ref |
| rows | 2,976,832 | 48,726 |
| Query_time | 18.42s | 0.06s |
| Extra | Using filesort | Using index condition |
Handler 状态对比也印证了索引的生效:Handler_read_key 从接近于 0 变为 48,728,说明索引被有效使用。
避坑建议
- 慢查询日志必须配:
long_query_time设 0.5~1 秒,接入监控告警 - SQL Review 卡口:上线前必须贴 EXPLAIN,type=ALL 的 SQL 禁止上线
- 复合索引优先单列索引:业务查询往往是多条件组合,单列索引覆盖能力有限
- 关注 Extra 中的 Using filesort:排序不走索引往往是性能杀手
- 测试数据量不能太小:几千行 vs 百万行,执行计划可能完全不同
附:完整命令清单
-- 查看连接数和慢查询配置
SHOW GLOBAL STATUS LIKE '%Threads_connected%';
SHOW GLOBAL STATUS LIKE '%Threads_running%';
SHOW VARIABLES LIKE 'slow_query_log%';
SHOW VARIABLES LIKE 'long_query_time';
-- 开启慢查询日志(生产谨慎设置,低阈值会增加 IO 开销)
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 0.5;
SET GLOBAL log_queries_not_using_indexes = ON;
-- EXPLAIN 分析
EXPLAIN SELECT ... \G
EXPLAIN FORMAT=JSON SELECT ... \G
-- 加索引
ALTER TABLE orders ADD INDEX idx_status_time (order_status, create_time);
ALTER TABLE orders ADD INDEX idx_status_time_cover (order_status, create_time, id, order_no, user_id, store_name, total_amount);
-- 更新统计信息
ANALYZE TABLE orders;
-- 查看索引使用情况
SHOW STATUS LIKE 'Handler_read%';


